Оригинальная статья: October 2024
Перевод: November 2024
Авторы: Маттиас Ресо, Анкит Гунапал, Саймон Мо, Ли Нин, Хамид Шоджаназери
Движок vLLM в настоящее время является одним из самых эффективных способов запуска больших языковых моделей (LLM). Он предоставляет команду vllm serve как простой вариант развертывания модели на одной машине. Хотя это и удобно, для обслуживания этих LLM в производственной среде и при масштабировании необходимы некоторые расширенные функции.
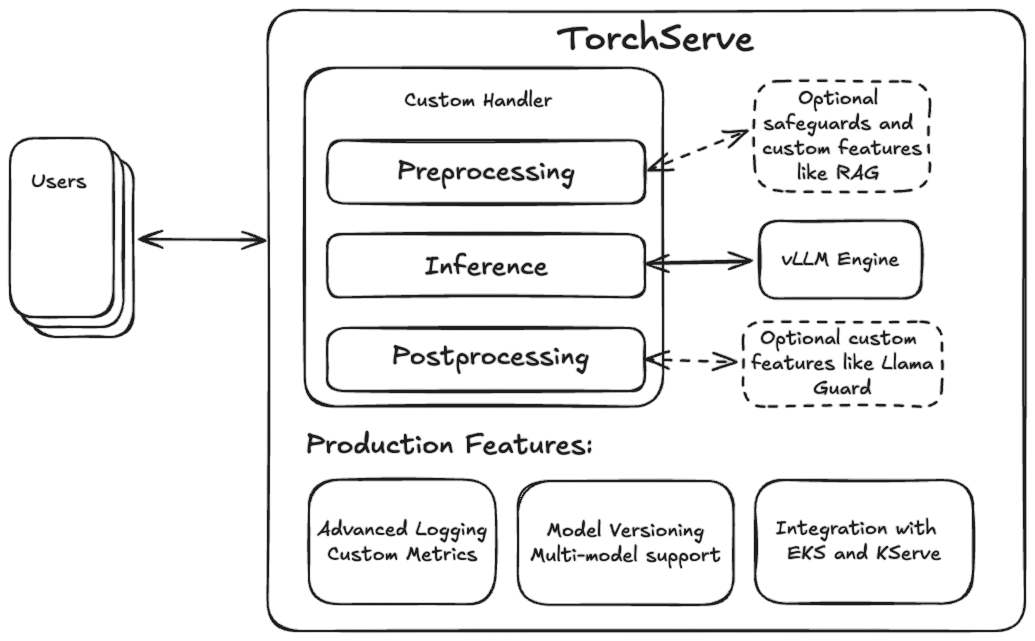
TorchServe предлагает эти важные производственные функции (такие как пользовательские метрики и версионирование моделей), и благодаря гибкому дизайну пользовательских обработчиков делает очень простой интеграцию таких функций, как генерация с дополненным поиском (RAG) или защитные механизмы, подобные Llama Guard. Поэтому естественно объединить движок vLLM с TorchServe для создания полнофункционального производственного решения по обслуживанию LLM.
Прежде чем углубиться в особенности интеграции, мы продемонстрируем развертывание модели Llama-3.1-70B-Instruct с использованием docker-образа vLLM от TorchServe.
Быстрый старт с Llama 3.1 на TorchServe + vLLM
Для начала нам необходимо собрать новый Docker-образ TS LLM, клонировав репозиторий TorchServe и выполнив следующую команду из основной директории:
docker build --pull . -f docker/Dockerfile.vllm -t ts/vllm
Контейнер использует наш новый скрипт запуска LLM ts.llm_launcher, который принимает URI модели Hugging Face или локальную папку и запускает локальный экземпляр TorchServe с движком vLLM, работающим в бэкенде. Чтобы запустить модель локально, вы можете создать экземпляр контейнера следующей командой:
#export token=<HUGGINGFACE_HUB_TOKEN>
docker run --rm -ti --shm-size 10g --gpus all -e HUGGING_FACE_HUB_TOKEN=$token -p
8080:8080 -v data:/data ts/vllm --model_id meta-llama/Meta-Llama-3.1-70B-Instruct --disable_token_auth
Вы можете протестировать конечную точку локально с помощью следующей команды curl:
curl -X POST -d '{"model":"meta-llama/Meta-Llama-3.1-70B-Instruct", "prompt":"Hello, my name is", "max_tokens": 200}' --header "Content-Type: application/json" "http://localhost:8080/predictions/model/1.0/v1/completions"
Docker хранит веса модели в локальной папке “data”, которая монтируется как /data внутри контейнера. Чтобы использовать свои собственные локальные веса, просто скопируйте их в папку data и укажите model_id как /data/<ваши веса>.
Внутри контейнера используется наш новый скрипт ts.llm_launcher для запуска TorchServe и развертывания модели. Этот загрузчик упрощает развертывание LLM с помощью TorchServe до одной команды и может также использоваться вне контейнера как эффективный инструмент для экспериментов и тестирования. Чтобы использовать загрузчик вне Docker, следуйте инструкциям по установке TorchServe, а затем выполните следующую команду для запуска модели Llama размером 8B:
# after installing TorchServe and vLLM run
python -m ts.llm_launcher --model_id meta-llama/Meta-Llama-3.1-8B-Instruct --disable_token_auth
При наличии нескольких GPU загрузчик автоматически задействует все видимые устройства и применит тензорный параллелизм (см. CUDA_VISIBLE_DEVICES для указания используемых GPU).
Хотя это очень удобно, важно отметить, что данный подход не охватывает все функциональные возможности TorchServe. Для тех, кто хочет использовать более продвинутые функции, необходимо создать архив модели. Хотя этот процесс немного сложнее, чем выполнение одной команды, он дает преимущества в виде пользовательских обработчиков и версионирования. Первое позволяет реализовать RAG на этапе предварительной обработки, а второе дает возможность тестировать различные версии обработчика и модели перед масштабным развертыванием.
Прежде чем предоставить подробные шаги по созданию и развертыванию архива модели, давайте углубимся в детали интеграции движка vLLM.
Интеграция движка vLLM в TorchServe
Как современный фреймворк для обслуживания моделей, vLLM предлагает множество передовых функций, включая PagedAttention, непрерывную пакетную обработку, быстрое выполнение моделей через графы CUDA и поддержку различных методов квантизации, таких как GPTQ, AWQ, INT4, INT8 и FP8. Он также обеспечивает интеграцию важных методов эффективной параметризации адаптеров, таких как LoRA, и доступ к широкому спектру архитектур моделей, включая Llama и Mistral. vLLM поддерживается командой vLLM и активным сообществом разработчиков с открытым исходным кодом.
Для упрощения быстрого развертывания он предлагает режим обслуживания на основе FastAPI для работы с LLM через HTTP. Для более тесной и гибкой интеграции проект также предоставляет vllm.LLMEngine, который предлагает интерфейсы для непрерывной обработки запросов. Мы использовали асинхронный вариант для интеграции с TorchServe.
TorchServe - это простое в использовании решение с открытым исходным кодом для обслуживания моделей PyTorch в производственной среде. Как проверенное в производстве решение для обслуживания, TorchServe предлагает множество преимуществ и функций, полезных для масштабного развертывания моделей PyTorch. Благодаря объединению с производительностью вывода движка vLLM эти преимущества теперь также можно использовать для масштабного развертывания LLM.

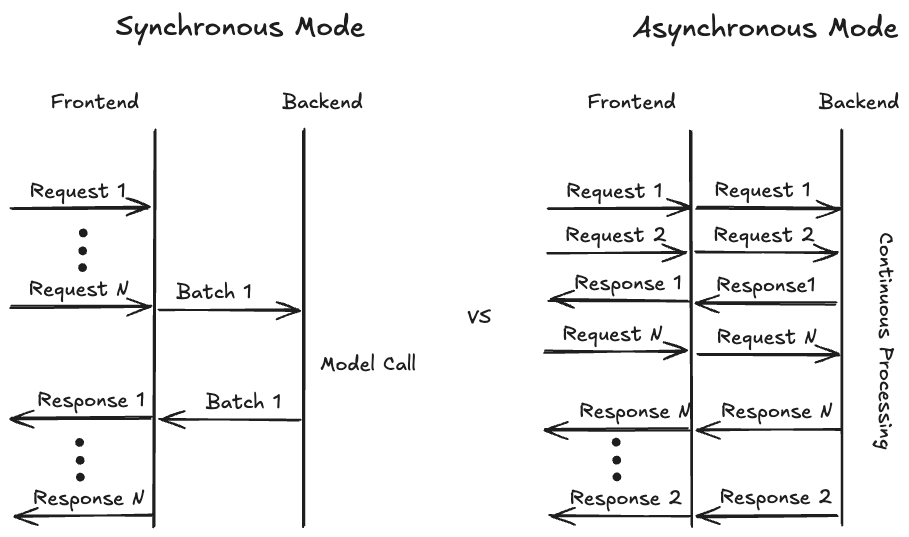
Для максимального использования аппаратных ресурсов обычно рекомендуется объединять запросы от нескольких пользователей в пакеты. Исторически TorchServe предлагал только синхронный режим для сбора запросов от различных пользователей. В этом режиме TorchServe ожидает заранее определенное время (например, batch_delay=200мс) или пока не накопится достаточное количество запросов (например, batch_size=8). Когда срабатывает одно из этих условий, пакетные данные передаются в бэкенд, где модель обрабатывает пакет, и результат возвращается пользователям через фронтенд. Это особенно хорошо работает для традиционных моделей компьютерного зрения, где обработка каждого запроса обычно завершается одновременно.
Для генеративных задач, особенно генерации текста, предположение об одновременной готовности запросов больше не является верным, так как ответы будут иметь разную длину. Хотя TorchServe поддерживает непрерывную пакетную обработку (возможность динамически добавлять и удалять запросы), этот режим поддерживает только статический максимальный размер пакета. С внедрением PagedAttention даже это ограничение максимального размера пакета становится более гибким, поскольку vLLM может комбинировать запросы различной длины адаптивным способом для оптимизации использования памяти.
Для достижения оптимального использования памяти, то есть для заполнения неиспользуемых участков памяти (как в игре Тетрис), vLLM требуется полный контроль над решением о том, какие запросы обрабатывать в каждый момент времени. Чтобы обеспечить такую гибкость, нам пришлось пересмотреть способ обработки пользовательских запросов в TorchServe. Вместо предыдущего синхронного режима обработки мы внедрили асинхронный режим (см. диаграмму ниже), где входящие запросы напрямую передаются в бэкенд, становясь доступными для vLLM. Бэкенд передает данные в vllm.AsyncEngine, который теперь может выбирать из всех доступных запросов. Если включен режим потоковой передачи и первый токен запроса доступен, бэкенд немедленно отправляет результат и продолжает отправлять токены до генерации последнего токена.
Наша реализация VLLMHandler позволяет пользователям быстро развертывать любую модель, совместимую с vLLM, используя конфигурационный файл, сохраняя при этом тот же уровень гибкости и настраиваемости через пользовательский обработчик. Пользователи могут свободно добавлять, например, пользовательские этапы предварительной обработки или пост-обработки, наследуясь от VLLMHandler и переопределяя соответствующие методы класса.
Мы также поддерживаем распределенный вывод на одном узле с несколькими GPU, где мы настраиваем vLLM на использование тензорного параллельного шардинга модели для увеличения емкости небольших моделей или обеспечения работы более крупных моделей, которые не помещаются на одном GPU, таких как варианты Llama размером 70B. Ранее TorchServe поддерживал распределенный вывод только с использованием torchrun, где для шардинга модели запускалось несколько фоновых рабочих процессов. vLLM управляет созданием этих процессов внутренне, поэтому мы внедрили новый тип параллелизма “custom” в TorchServe, который запускает один фоновый рабочий процесс и предоставляет список назначенных GPU. Затем фоновый процесс может при необходимости запускать собственные подпроцессы.
Для упрощения интеграции TorchServe + vLLM в развертывания на основе Docker мы предоставляем отдельный Dockerfile, основанный на GPU-образе Docker для TorchServe, с добавленной зависимостью vLLM. Мы решили сохранить их раздельными, чтобы избежать увеличения размера docker-образа для развертываний, не связанных с LLM.
Далее мы продемонстрируем шаги, необходимые для развертывания модели Llama 3.1 70B с использованием TorchServe + vLLM на машине с четырьмя GPU.
Пошаговое руководство
Для этого пошагового руководства мы предполагаем, что установка TorchServe успешно завершена. В настоящее время vLLM не является обязательной зависимостью для TorchServe, поэтому давайте установим пакет с помощью pip:
$ pip install -U vllm==0.6.1.post2
В следующих шагах мы (опционально) загрузим веса модели, объясним конфигурацию, создадим архив модели, развернем и протестируем ее:
1. (Опционально) Загрузка весов модели
Этот шаг является необязательным, так как vLLM может также загрузить веса при запуске сервера модели. Однако предварительная загрузка весов модели и совместное использование кэшированных файлов между экземплярами TorchServe может быть полезным с точки зрения использования хранилища и времени запуска рабочего процесса модели. Если вы решите загрузить веса, используйте huggingface-cli и выполните:
# убедитесь, что вы авторизовались в huggingface с помощью huggingface-cli login
# и ваш запрос на доступ к весам модели Llama 3.1 был одобрен
huggingface-cli download meta-llama/Meta-Llama-3.1-70B-Instruct --exclude original/*
Это загрузит файлы в директорию $HF_HOME. Вы можете изменить эту переменную, если хотите разместить файлы в другом месте. Убедитесь, что вы обновили значение переменной везде, где запускаете TorchServe, и что у него есть доступ к этой папке.
2. Настройка модели
Далее мы создадим конфигурационный файл YAML, содержащий все необходимые параметры для развертывания нашей модели. Первая часть конфигурационного файла определяет, как фронтенд должен запускать рабочий процесс бэкенда, который в конечном итоге будет выполнять модель в обработчике. Вторая часть включает параметры для обработчика бэкенда, такие как модель для загрузки, а также различные параметры для самого vLLM. Для получения дополнительной информации о возможных конфигурациях движка vLLM, пожалуйста, обратитесь к этой ссылке.
echo '
# TorchServe frontend parameters
minWorkers: 1
maxWorkers: 1 # Установить количество рабочих процессов для создания единственного экземпляра модели
startupTimeout: 1200 # (в секундах) Время, отведенное рабочему процессу на загрузку весов модели
deviceType: "gpu"
asyncCommunication: true # Обеспечивает асинхронное взаимодействие с рабочим процессом
parallelType: "custom" # Позволяет TorchServe создать один процесс бэкенда с назначением 4 GPU
parallelLevel: 4
# Параметры обработчика
handler:
# model_path can be a model identifier for Hugging Face hub or a local path
model_path: "meta-llama/Meta-Llama-3.1-70B-Instruct"
vllm_engine_config: # vLLM configuration which gets fed into AsyncVLLMEngine
max_num_seqs: 16
max_model_len: 512
tensor_parallel_size: 4
served_model_name:
- "meta-llama/Meta-Llama-3.1-70B-Instruct"
- "llama3"
'> model_config.yaml
3. Создание папки модели
После создания конфигурационного файла модели (model_config.yaml), мы создадим архив модели, который включает конфигурацию и дополнительные метаданные, такие как информация о версионировании. Поскольку веса модели имеют большой размер, мы не будем включать их в архив. Вместо этого обработчик будет получать доступ к весам, следуя пути model_path, указанному в конфигурации модели. Обратите внимание, что в этом примере мы решили использовать формат “no-archive”, который создает папку модели, содержащую все необходимые файлы. Это позволяет нам легко модифицировать конфигурационные файлы для экспериментов без каких-либо затруднений. Позже мы также можем выбрать формат mar или tgz для создания более удобного для переноса артефакта.
mkdir model_store
torch-model-archiver --model-name vllm --version 1.0 --handler vllm_handler --config-file model_config.yaml --archive-format no-archive --export-path model_store/
4. Развертывание модели
Следующим шагом является запуск экземпляра TorchServe и загрузка модели. Обратите внимание, что мы отключили аутентификацию токенов для целей локального тестирования. Настоятельно рекомендуется реализовать какую-либо форму аутентификации при публичном развертывании любой модели.
Для запуска экземпляра TorchServe и загрузки модели выполните следующую команду:
torchserve --start --ncs --model-store model_store --models vllm --disable-token-auth
Вы можете отслеживать прогресс загрузки модели через сообщения в логах. После того как модель будет полностью загружена, можно приступать к тестированию развертывания.
5. Тестирование развертывания
Интеграция vLLM использует формат, совместимый с OpenAI API, поэтому мы можем использовать либо специализированный инструмент для этой цели, либо curl. JSON-данные, которые мы здесь используем, включают идентификатор модели и текст запроса. Другие параметры и их значения по умолчанию можно найти в документации vLLMEngine.
echo '{
"model": "llama3",
"prompt": "A robot may not injure a human being",
"stream": 0
}' | curl --header "Content-Type: application/json" --request POST --data-binary @- http://localhost:8080/predictions/vllm/1.0/v1/completions
Результат запроса выглядит следующим образом:
{
"id": "cmpl-cd29f1d8aa0b48aebcbff4b559a0c783",
"object": "text_completion",
"created": 1727211972,
"model": "meta-llama/Meta-Llama-3.1-70B-Instruct",
"choices": [
{
"index": 0,
"text": " or, through inaction, allow a human being to come to harm.\nA",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 26,
"completion_tokens": 16
}
Когда параметр stream установлен в False, TorchServe соберет полный ответ и отправит его одним пакетом после создания последнего токена. Если мы изменим параметр stream, то будем получать данные по частям, где каждое сообщение содержит один токен.
Заключение
В этой статье мы рассмотрели новую, нативную интеграцию движка вывода vLLM в TorchServe. Мы продемонстрировали, как локально развернуть модель Llama 3.1 70B с помощью скрипта ts.llm_launcher и как создать архив модели для развертывания на любом экземпляре TorchServe. Кроме того, мы обсудили, как собрать и запустить решение в Docker-контейнере для развертывания в Kubernetes или EKS. В будущих работах мы планируем реализовать многоузловой вывод с помощью vLLM и TorchServe, а также предложить готовый Docker-образ для упрощения процесса развертывания.
Мы хотели бы выразить благодарность Марку Саруфиму и команде vLLM за их неоценимую поддержку при подготовке этой статьи.