Тренировка современных моделей машинного обучения становится все более требовательной вычислительной задачей. По мере того как модели масштабируются до сотен миллиардов или даже триллионов параметров, а датасеты растут до беспрецедентных размеров, подходы с использованием одного устройства становятся нереализуемыми. Рассмотрим GPT-4 с его оценочными 1,8 триллионами параметров: тренировка такой модели на одном GPU заняла бы несколько тысячелетий 1.
Для решения этих вычислительных задач инженеры разработали сложные стратегии распределенного обучения. Одна из таких стратегий — распределенный параллелизм данных.
Distributed Data Parallelism
Data Parallelism позволяет устранить узкое место вычислений при обучении, распределяя пакеты обучающих данных между несколькими графическими процессорами, при этом каждое устройство содержит полную копию модели. Такой подход обеспечивает параллельную обработку различных образцов данных при сохранении неизменной архитектуры модели, что значительно сокращает время обучения за счёт повышения пропускной способности.
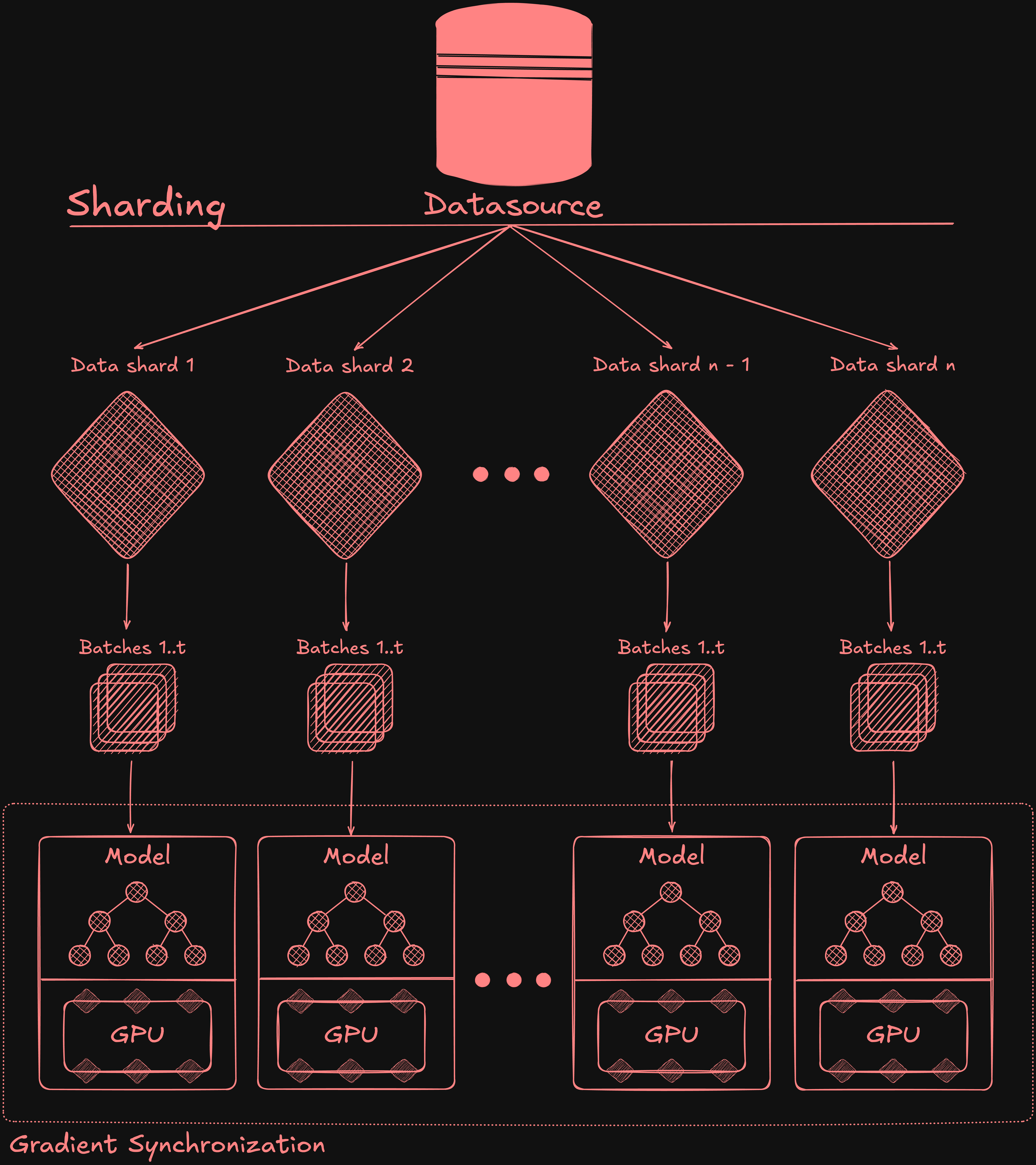 Иллюстрация подхода распределённого параллелизма данных при обучении
Иллюстрация подхода распределённого параллелизма данных при обучении
Градиенты синхронизируются между устройствами после обратного прохода мини-батча 2, обеспечивая, что все устройства имеют одинаковые суммарные градиенты перед этапом обновления весов. В ходе этой синхронизации локальные градиенты каждого устройства объединяются, и результат распределяется обратно по всем узлам, что позволяет им согласованно обновлять параметры модели.
Важно отметить, что эта стратегия работает только в том случае, если вся модель помещается в память устройства, что может стать критическим ограничением по мере увеличения размеров модели. Эта стратегия идеальна для сценариев с большими наборами данных и относительно небольшими моделями (обычно менее нескольких миллиардов параметров), что делает её отличным выбором для многих задач компьютерного зрения.
Кроме того, при использовании распределённого параллелизма данных для обучения модели необходимо учитывать, что эффективный размер батча увеличивается с числом GPU. Это может потребовать корректировки скорости обучения и других гиперпараметров для обеспечения сходимости модели.
Для синхронизации градиентов в рамках обучения с параллельной обработкой данных можно использовать различные алгоритмы и схемы коммуникации. Одним из популярных подходов является алгоритм ring all-reduce.
Алгоритм Ring All-Reduce
Алгоритм кольцевого all-reduce — это коммуникационный алгоритм, который пытается эффективно решать задачу объединения данных на нескольких устройствах/машинах.
При использовании базовых методов, когда все процессоры отправляют свои данные на один мастер-узел для объединения, накладные расходы на связь растут линейно в зависимости от количества процессоров, что создаёт существенное узкое место, ограничивающее масштабируемость.
Например, при условии, что N устройств, каждое из которых отправляет D байт данных, мастер-узел должен получать и обрабатывать N×D байт данных, при этом становясь сетевым узким местом, поскольку он обрабатывает N отдельных входящих соединений.
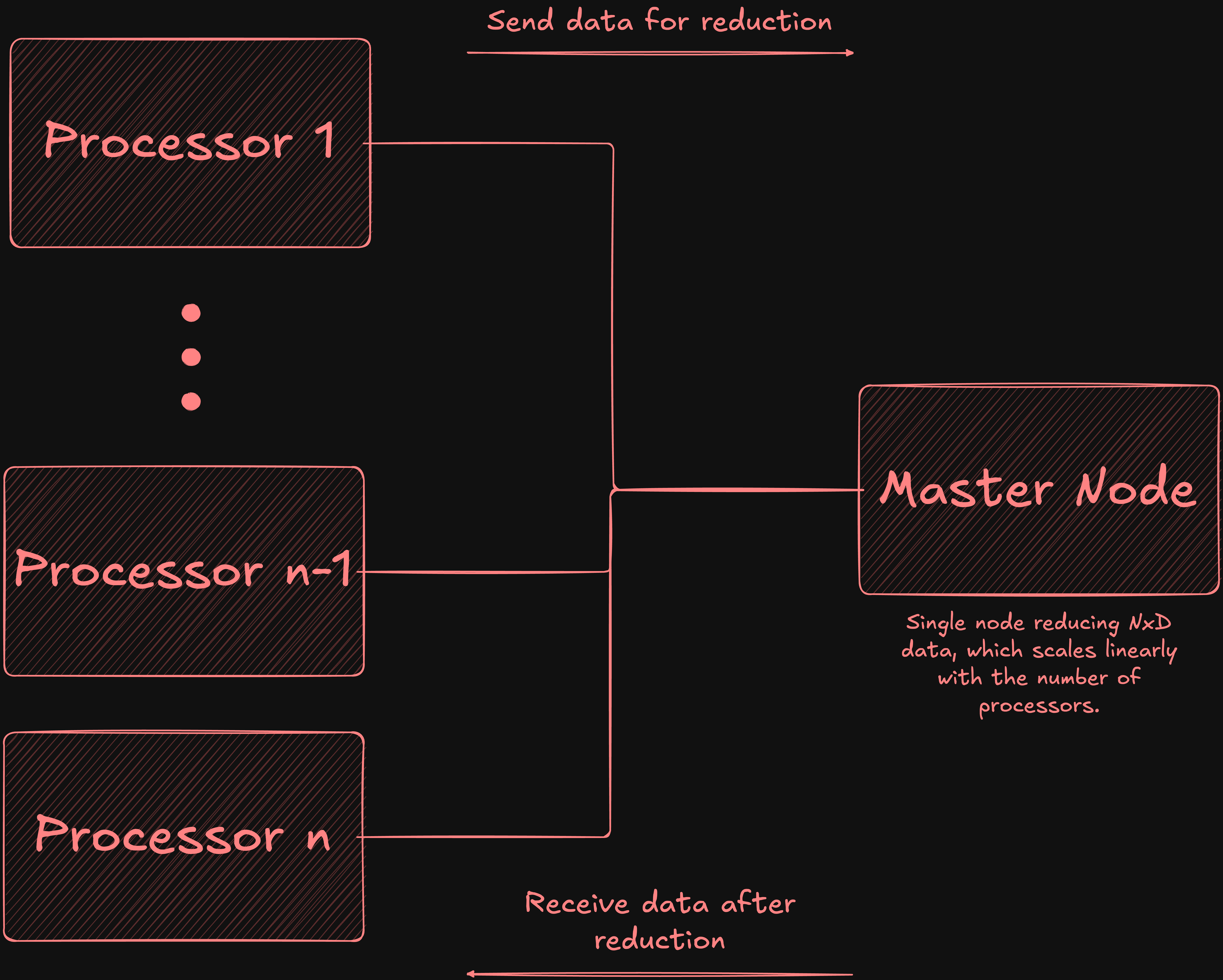 Объединение данных на одном мастер-узле
Объединение данных на одном мастер-узле
Алгоритм кольцевого all-reduce располагает процессоры в логическом кольце, где каждый обменивается данными только со своими непосредственными соседями. Алгоритм выполняется в две фазы: scatter-reduce и all-gather. Во время фазы scatter-reduce каждое устройство делит свои локальные данные на равные части (по одной на каждый процессор) и постепенно обменивается и сводит (редуцирует) эти части по мере их перемещения по кольцу. Начиная с i = 0 и используя циклическую индексацию частей, для процессора p шаги можно определить следующим образом:
- Отправляет p - i к процессору p + 1.
- Получает часть p - i - 1 и сводит её с локальной частью.
- Увеличивает i и повторяет, пока i < p - 1.
В конце этой фазы каждый процессор держит полностью уменьшенную (обобщённую) часть.
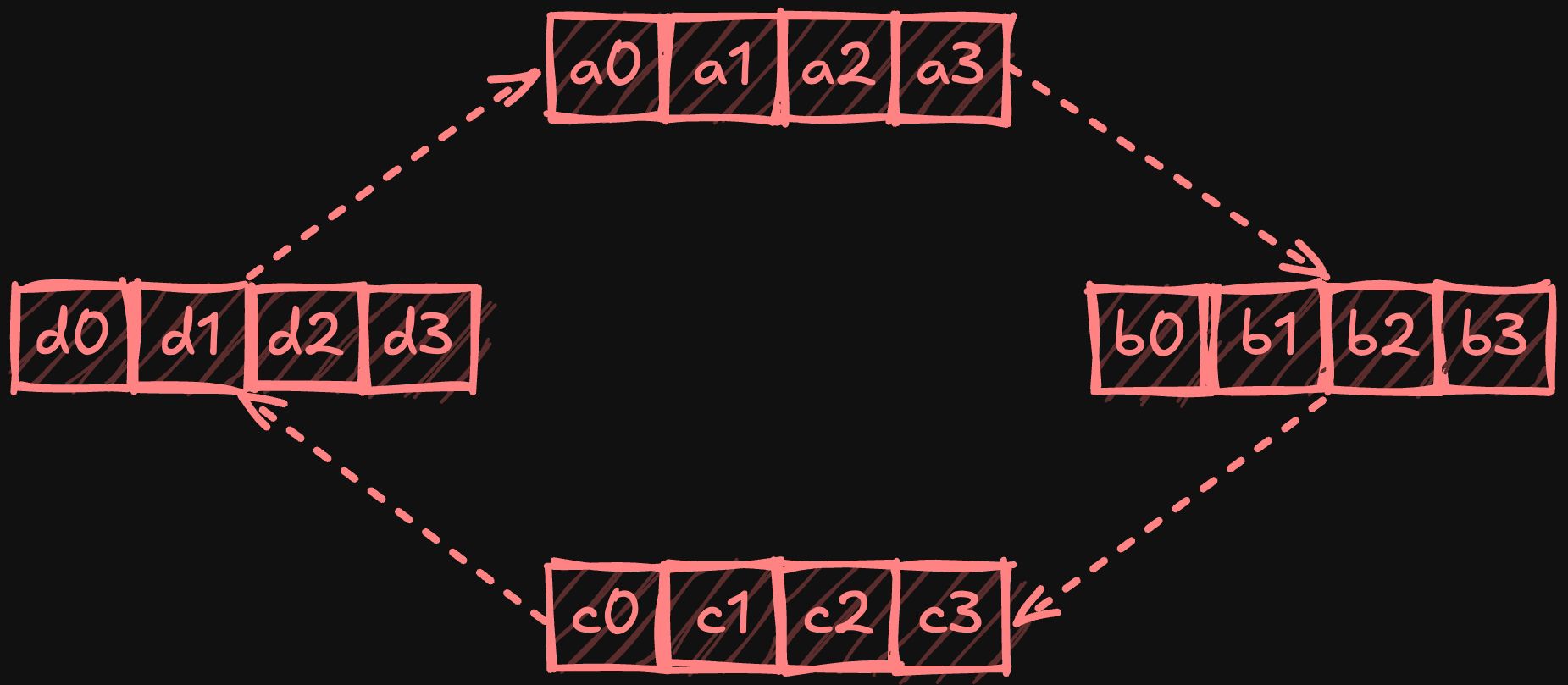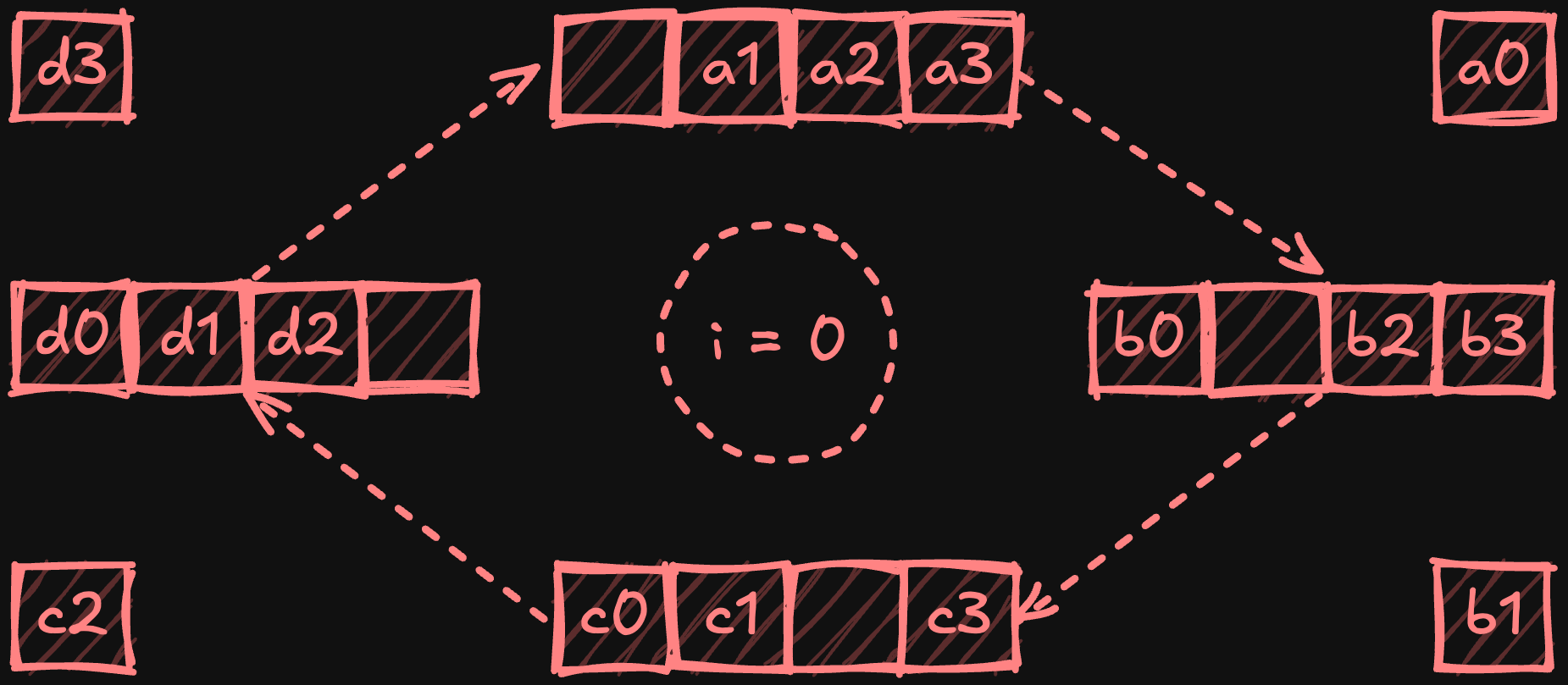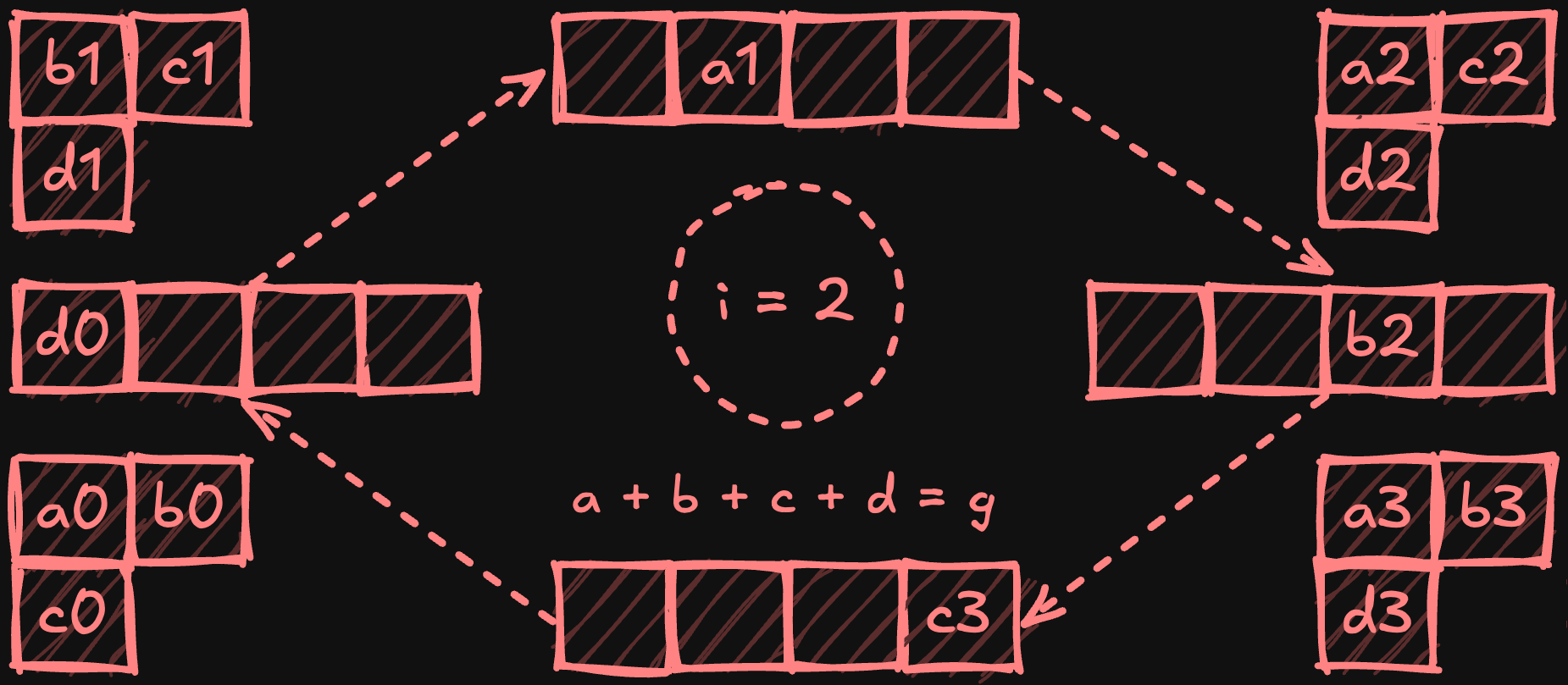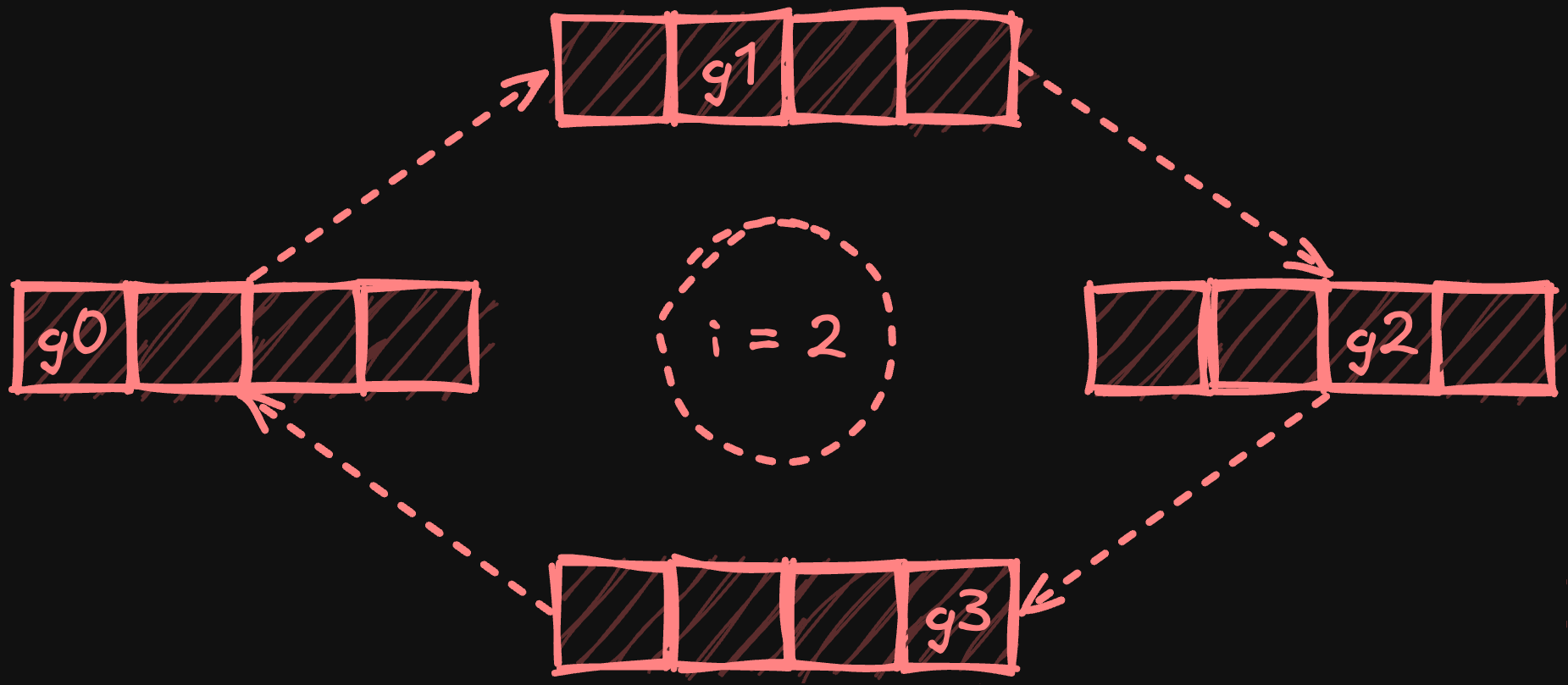 Иллюстрация фазы scatter-reduce с четырьмя процессорами
Иллюстрация фазы scatter-reduce с четырьмя процессорами
В последующей фазе all-gather процессоры обмениваются уменьшенными фрагментами по кольцу, при этом каждый процессор собирает копию каждого фрагмента. После N-1 шага (где N — количество процессоров) каждый процессор получает полную копию полностью уменьшенных фрагментов.
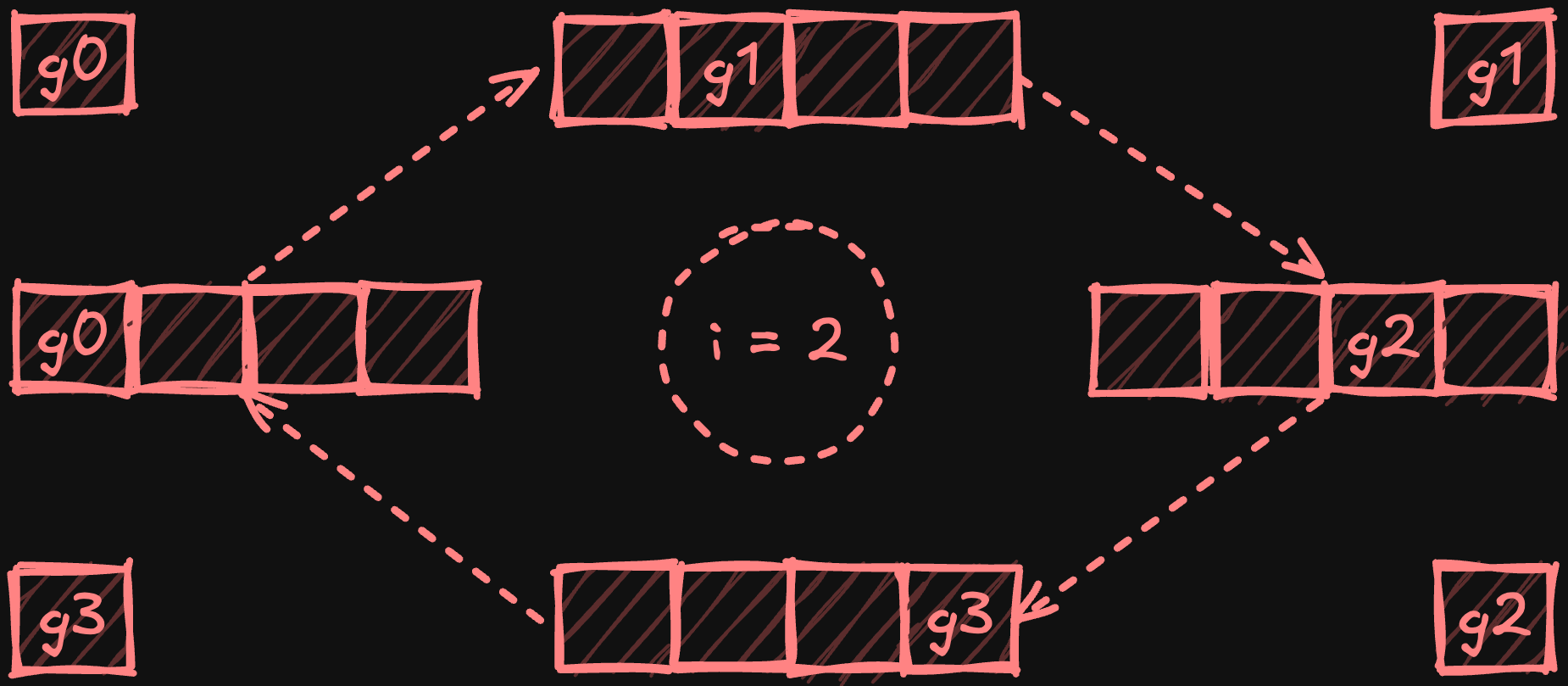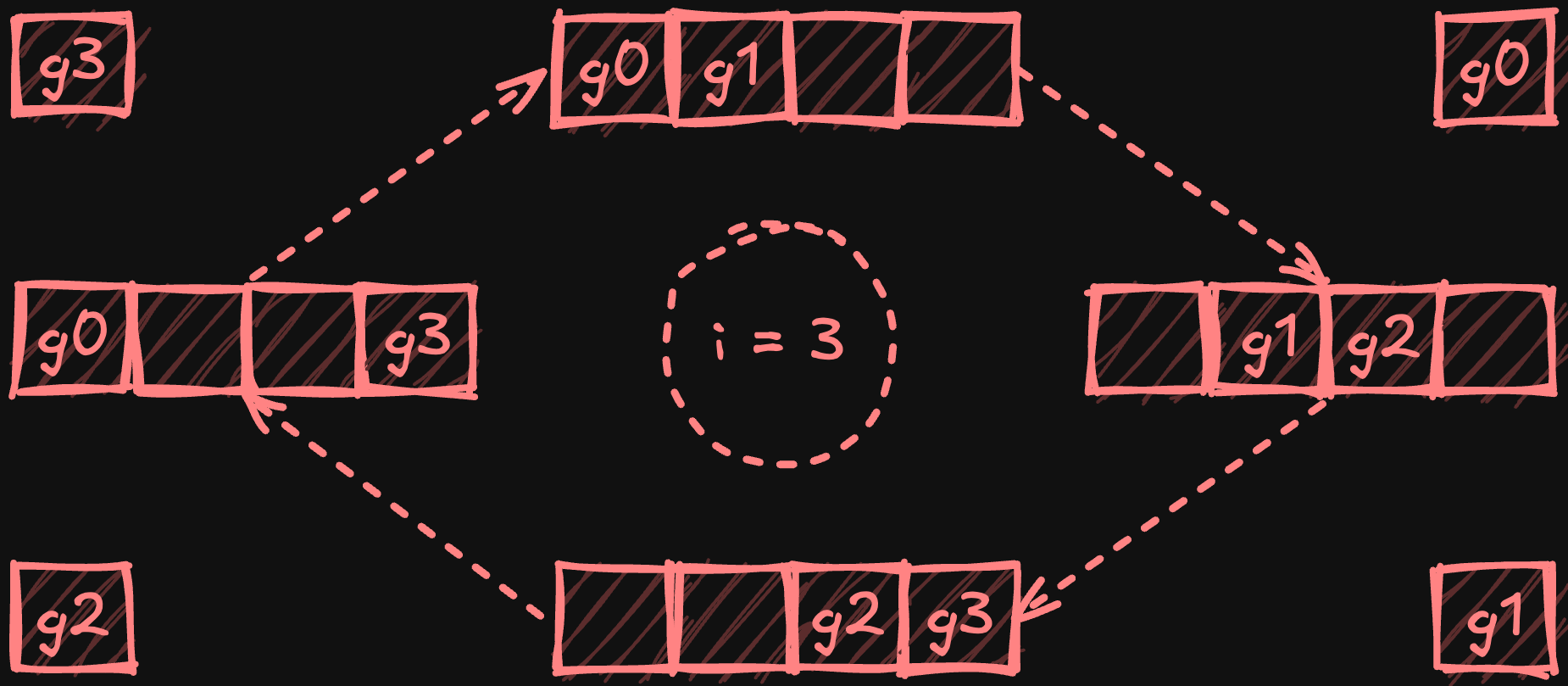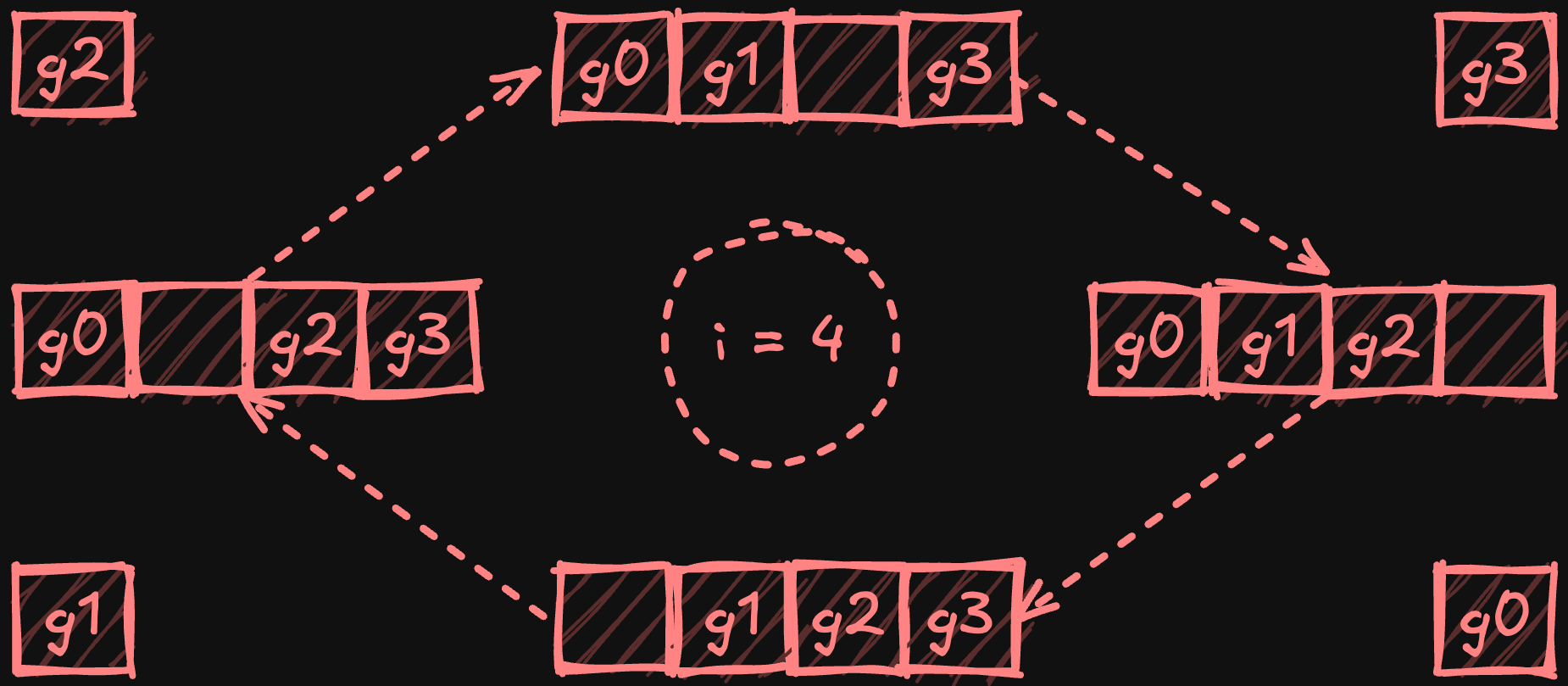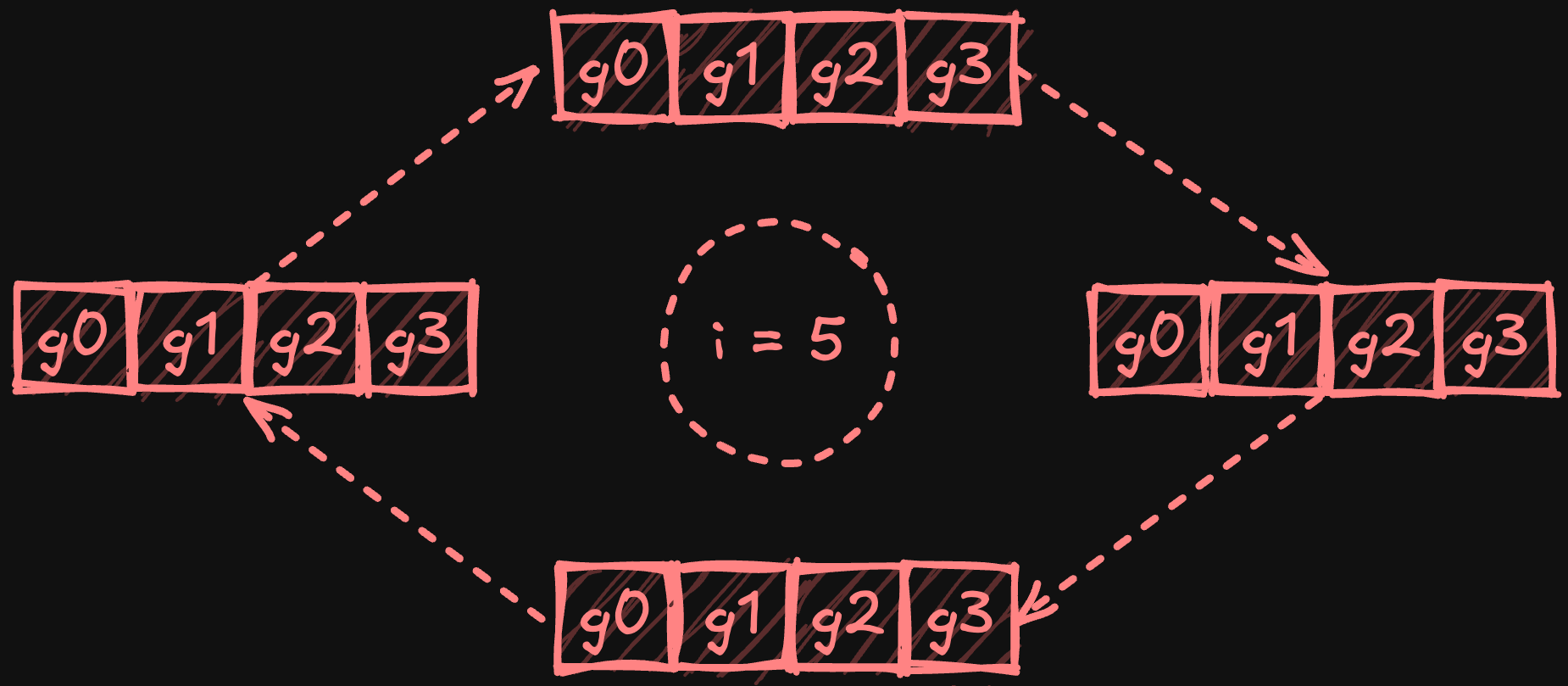 Иллюстрация фазы all-gather с четырьмя процессорами
Иллюстрация фазы all-gather с четырьмя процессорами
Общее количество переданных данных в алгоритме кольцевого all-reduce можно выразить следующим образом:
$$ \frac{2(N-1)K}{N} \approx 2K $$
Эта формула отражает двухфазную структуру алгоритма: N-1 шагов для scatter-reduce и N-1 шагов для all-gather, что даёт нам множитель 2(N-1). На каждом шаге устройства обмениваются фрагментами размером K/N , поскольку исходные данные размером K делятся на N равных частей.
Эта формула упрощается до 2K, что показывает, что переданные данные остаются постоянными независимо от количества процессоров. При оптимальном расположении топологии GPU, алгоритм достигает оптимальности по использованию пропускной способности при пренебрежимо малых затратах на задержку по сравнению с ограничениями на пропускную способность.
Ring All-Reduce в Deep Learning
В Deep Learning алгоритм ring all-reduce обеспечивает эффективную синхронизацию градиентов при распределённом обучении на нескольких GPU или вычислительных узлах. В каждом цикле обучения каждый GPU вычисляет градиенты для своей локальной выборки данных, и эти градиенты необходимо усреднять между всеми устройствами для поддержания согласованности модели.
Кольцевой алгоритм all-reduce работает наиболее эффективно, когда GPU внутри одного узла расположены рядом друг с другом в кольце (логическая связь), что минимизирует сетевую нагрузку. Поскольку передача данных осуществляется синхронно между соседями, скорость работы алгоритма ограничена самым медленным соединением в кольце.
Дополнительное повышение производительности достигается за счет использования структуры нейронной сети по слоям: в каждой итерации, в то время как GPU выполняют прямое распространение (forward propagation) для вычисления ошибки, а затем обратное распространение (back propagation) для расчета градиента, градиенты появляются в порядке от последнего слоя к первому. Алгоритм ring all-reduce может начать синхронизировать градиенты последних слоёв, пока для первых слоёв они ещё только вычисляются. Это позволяет параллельно выполнять обмен данными и вычисления, значительно сокращая время простоя GPU.
В качестве примера можно привести распределенное обучение PyTorch в Kubernetes с помощью Kubeflow training operator, который использует алгоритм ring all-reduce.
Задержка алгоритма ring all-reduce
В крупных распределенных системах задержка играет значимую роль. Хотя алгоритм ring all-reduce обеспечивает оптимальное использование полосы пропускания в идеальных условиях, его характеристика задержки накладывает ограничения на масштабируемость. В каждом раунде синхронизации алгоритму необходимо выполнить 2(N-1) последовательных коммуникационных шага, где N — это количество участвующих процессоров. Это приводит к линейной зависимости между задержкой и числом процессоров, что становится проблемой в больших кластерах для обучения. Учитывая, насколько сетевые операции затратны с точки зрения вычислительных ресурсов, совокупное влияние этих коммуникационных шагов может значительно ухудшить общую производительность обучения при увеличении количества GPU или узлов в кластере.
Tree All-Reduce
Алгоритм tree all-reduce - это распределённая методика, использующая структуру бинарного дерева для эффективного с точки зрения задержек объединения данных между множеством узлов. Представьте себе перевернутое бинарное дерево: узлы на нижних уровнях отправляют данные своим родителям, которые в свою очередь объединяют полученные значения. Этот процесс требует log2(N) шагов, что значительно сокращает задержку по сравнению с алгоритмом кольцевого all-reduce, которому необходимо N шагов. Например, при работе с 1024 узлами tree all-reduce завершает выполнение всего за 10 коммуникационных шагов, тогда как кольцевой reduce требует 1024 шага. Рассмотрим процесс более подробно:
Фаза Reduce (уменьшение):
- Узлы-листья передают свои значения родительским узлам.
- Родительские узлы объединяют полученные значения и отправляют результат своим родителям.
- Этот процесс продолжается, пока не будет выполнено финальное объединение на корневом узле.
Фаза Broadcast (передача):
- Корневой узел передаёт результат двум своим дочерним узлам.
- Каждый родитель отправляет полученное значение двум своим дочерним узлам.
- Процесс продолжается до достижения листовых узлов.
Общая задержка составляет 2*log2(N) шагов: log2(N) для фазы reduce и log2(N) для фазы broadcast.
Визуализация алгоритма tree all-reduce
Основное ограничение связано с использованием пропускной способности. Конечные узлы, составляющие половину всех узлов, работают в полудуплексном режиме. Это значит, что они отправляют данные в фазе reduce и получают их в фазе broadcast, но никогда не используют свой потенциальный полнодуплексный режим, который позволяет одновременно отправлять и получать данные. Несмотря на то что конвейеризация может помочь внутренним узлам совмещать процессы отправки и получения, это не решает проблему конечных узлов. Они поочередно переключаются между отправкой и получением, вместо того чтобы делать это одновременно, что приводит к недоиспользованию доступной пропускной способности сети.
Two-Tree All-Reduce
Алгоритм two-tree all-reduce (предложенный Сандерсом, Траффом и Ларссоном в 2009 году) предназначен для решения проблемы низкого использования полосы пропускания в простых алгоритмах сокращения, основанных на деревьях. Он начинается с построения полного (но не обязательно полного) двоичного дерева, а затем создания дополнительного дерева. В одном дереве узел выступает в качестве листа, а в другом становится внутренним узлом. Путём «сдвига» или «отражения» нумерации от исходного полного дерева, внутренние узлы одного дерева совпадают с листьями другого, создавая идеально сплетённый шаблон коммуникации.
После создания этих двух дополнительных деревьев данные разделяются на две части. За исключением начальных этапов (когда данные впервые отправляются) и финальных этапов (когда последние данные доставляются), каждая промежуточная фаза коммуникации позволяет каждому процессору одновременно отправлять и получать данные, почти удваивая эффективное использование полосы пропускания по сравнению с подходом на основе одного дерева. Хотя не все этапы могут полностью использовать всю полосу пропускания из-за начальных и финальных фаз, большинство шагов достигает полноценной дуплексной эффективности. При этом алгоритм всё ещё работает с логарифмическим числом шагов, как и стандартный алгоритм tree all-reduce, что обеспечивает низкую общую задержку.
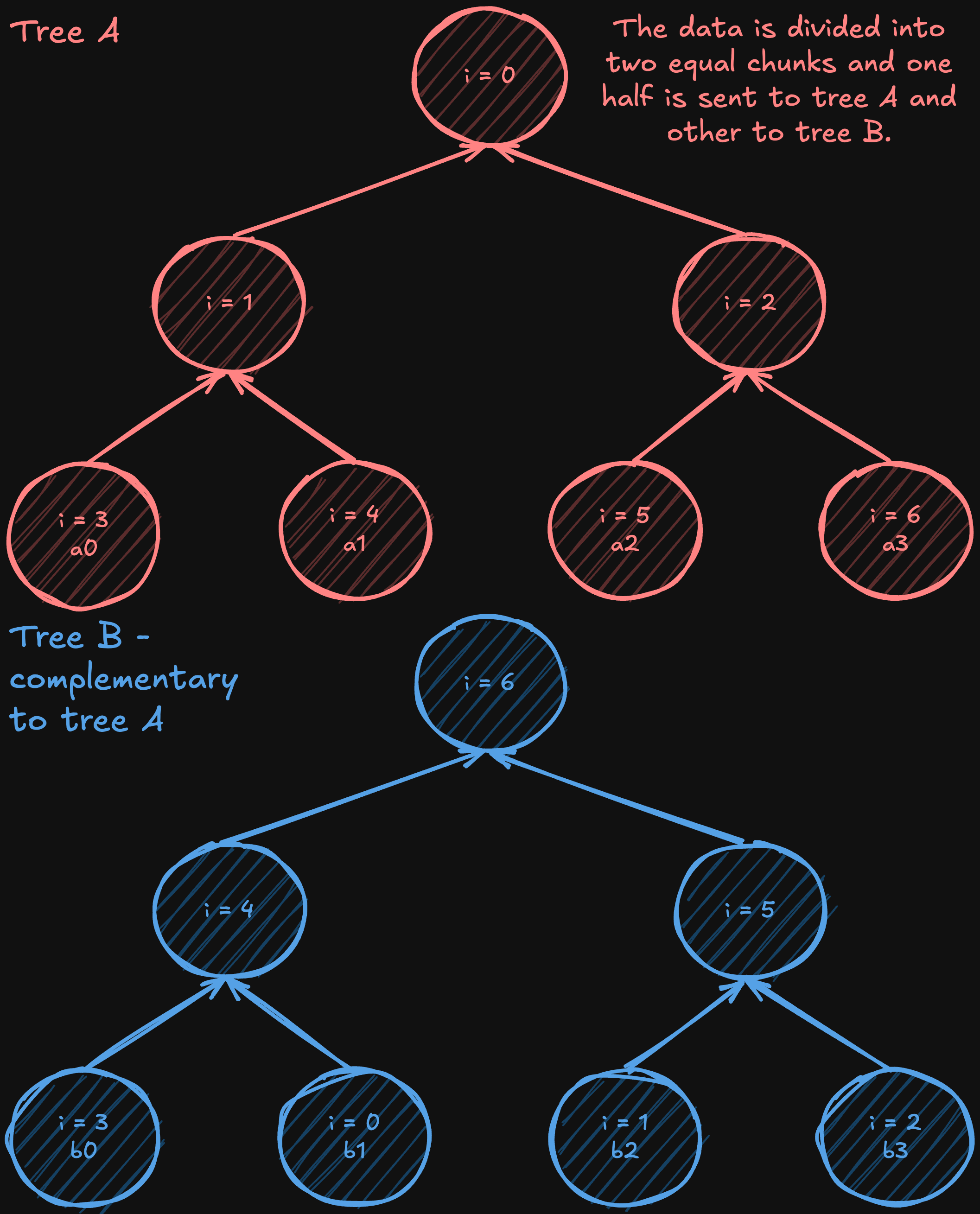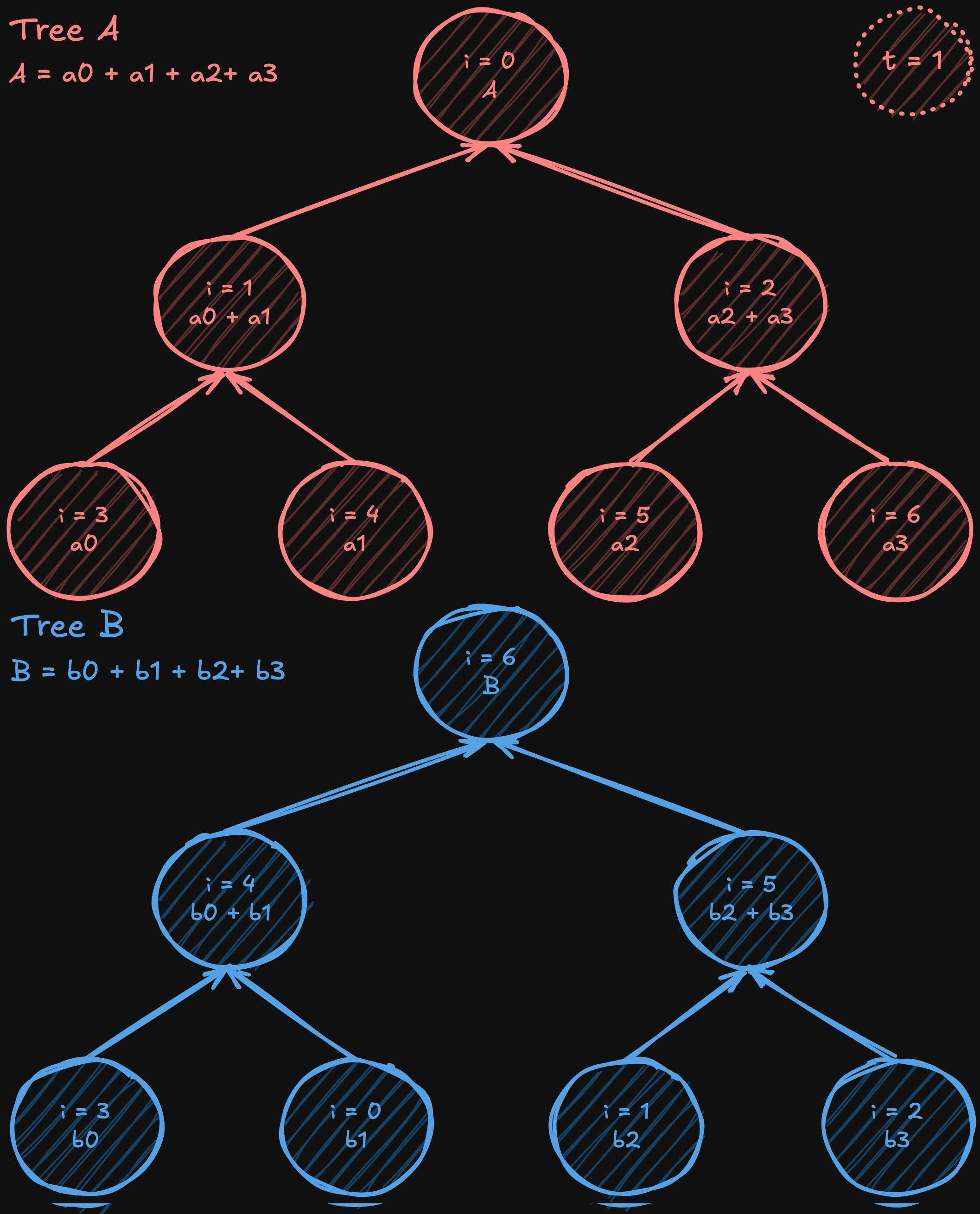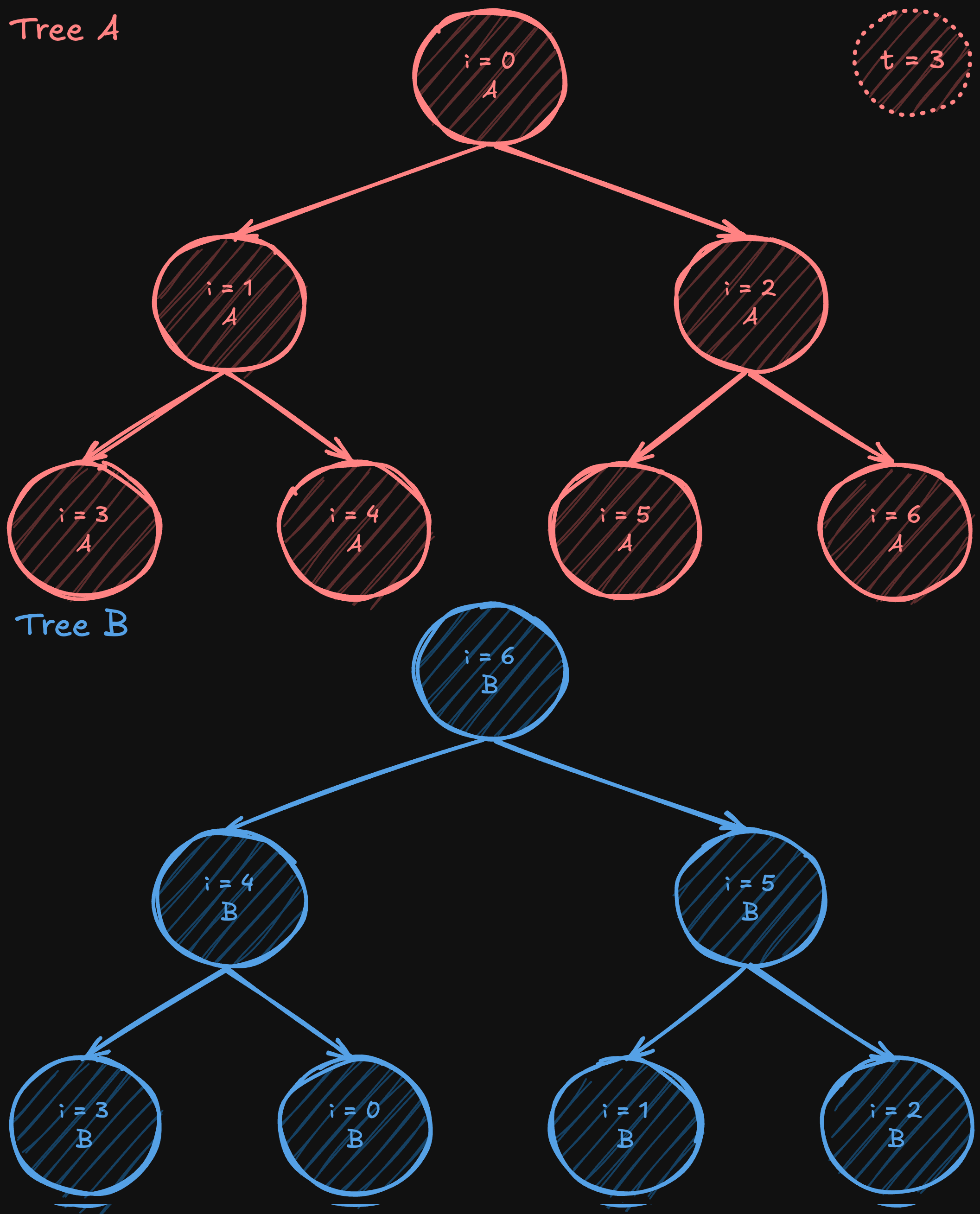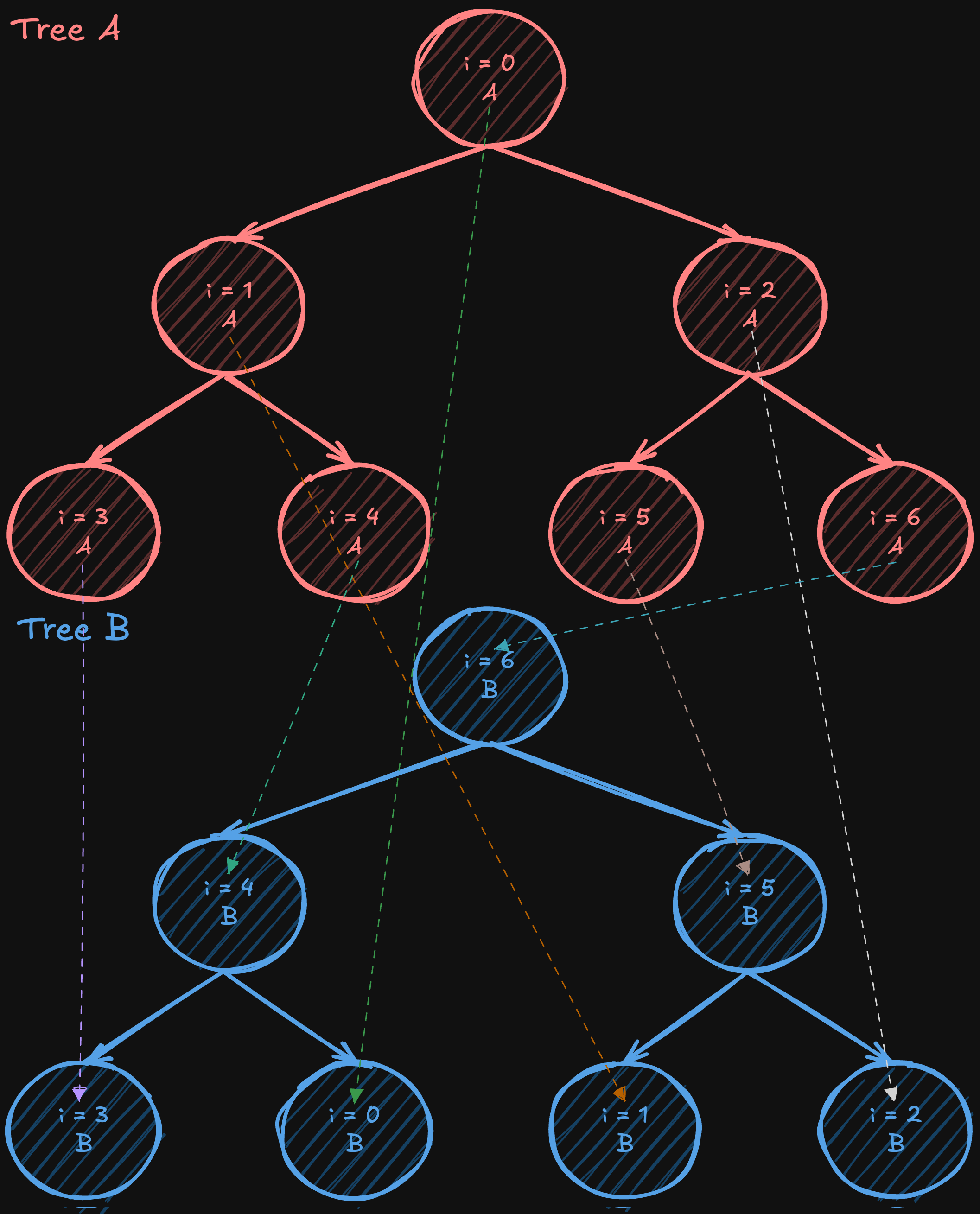 Визуализация алгоритма two-tree all-reduce
Визуализация алгоритма two-tree all-reduce
Алгоритм two-tree all-reduce сочетает в себе преимущества низкой задержки O(logN) методов, основанных на деревьях, с высокой пропускной способностью, что делает его привлекательным для использования в масштабных системах распределенного обучения.
Влияние на производительность
В 2019 году компания NVIDIA опубликовала статью «Масштабируйте обучение глубоких нейронных сетей с помощью NCCL 2.4», в которой был проведен анализ влияния различных алгоритмов all-reduce — ring all-reduce, hierarchical ring all-reduce и two-tree all-reduce — на производительность. Их результаты можно резюмировать следующим образом:
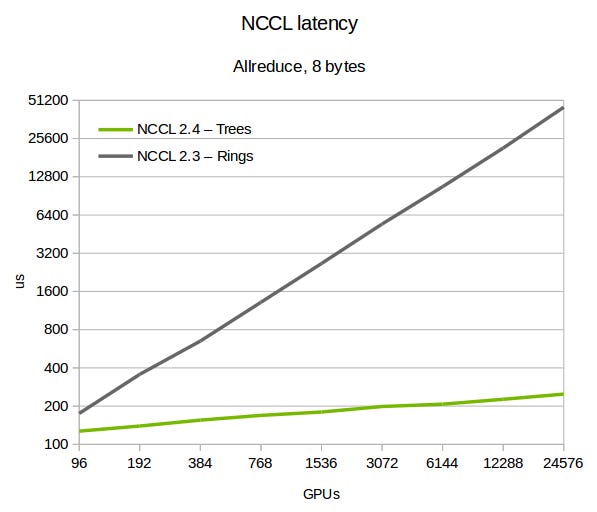 Задержка NVIDIA Collective Communications Library (NCCL) для различных алгоритмов all-reduce. Изображение взято из статьи “Massively Scale Your Deep Learning Training with NCCL 2.4”.
Задержка NVIDIA Collective Communications Library (NCCL) для различных алгоритмов all-reduce. Изображение взято из статьи “Massively Scale Your Deep Learning Training with NCCL 2.4”.
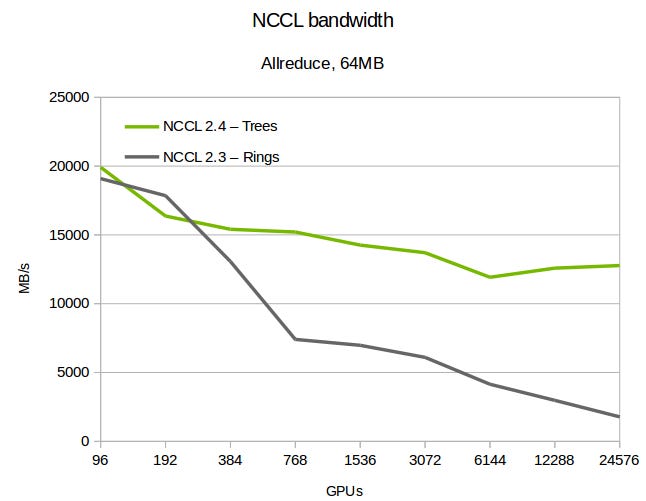 Пропускная способность NCCL для различных алгоритмов all-reduce. Изображение взято из статьи “Massively Scale Your Deep Learning Training with NCCL 2.4”.
Пропускная способность NCCL для различных алгоритмов all-reduce. Изображение взято из статьи “Massively Scale Your Deep Learning Training with NCCL 2.4”.
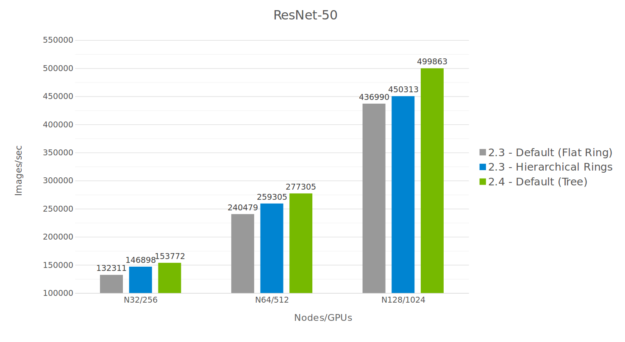 Сравнение производительности обучения на ResNet50. Разрыв в производительности между сравниваемыми подходами увеличивается с ростом количества GPU. Изображение взято из статьи “Massively Scale Your Deep Learning Training with NCCL 2.4”.
Сравнение производительности обучения на ResNet50. Разрыв в производительности между сравниваемыми подходами увеличивается с ростом количества GPU. Изображение взято из статьи “Massively Scale Your Deep Learning Training with NCCL 2.4”.
Заключение
В условиях стремительного роста современных моделей машинного обучения и увеличения объемов данных, обучение на одном устройстве быстро теряет свою практичность, требуя внедрения распределенных стратегий, таких как параллелизм данных, для использования возможностей нескольких GPU. В этих условиях важным фактором становятся накладные расходы на коммуникацию, где как пропускная способность, так и задержка играют ключевые роли в повышении эффективности обучения. Для синхронизации градиентов существуют алгоритмы, такие как двухдеревная all-reduce, которые объединяют преимущества низкой задержки дереваобразных методов с практически полной загрузкой пропускной способности, предлагая привлекательное и масштабируемое решение для обучения моделей в крупном масштабе.
Оригинальная статья на английском языке: Distributed Data Parallel Training
Согласно оценкам сообщества, обучение GPT-4 осуществлялось на кластере из 20,000-25,000 NVIDIA A100 GPU в течение 3-4 месяцев. Чтобы лучше понять масштабы, представьте, что попытка обучить ту же модель на одной A100 GPU (при условии линейного масштабирования) заняла бы от 5,000 до 8,300 лет. ↩︎
Как будет детально рассмотрено в следующих разделах статьи, более эффективные стратегии начинают синхронизацию градиентов сразу после подготовки их части, совмещая коммуникацию с вычислениями и сокращая время простоя GPU. ↩︎