В этой статье я поделюсь практическим опытом инференса LLM на двух серверах с разными GPU. Большие языковые модели требуют значительных вычислительных ресурсов (vRAM), и распределенный запуск с использованием инструментов, таких как Ray, может значительно упростить этот процесс. В процессе работы я столкнулся с проблемой неравномерного распределения ресурсов, поскольку видеокарты имеют разный объем vRAM, и половина модели изначально не помещалась на меньшую GPU.
Ray: основа распределенных вычислений
Ray представляет собой фреймворк для распределенных вычислений, который идеально подходит для наших задач. Его ключевые преимущества:
Бесшовное масштабирование: Ray позволяет пользователям легко масштабировать свои приложения от локальных сред до облачных инфраструктур. Это достигается с помощью простых примитивов и декоратора на Python, что делает его удобным для разработчиков.
Нативный Python с интеграциями экосистемы: Движок разработан с приоритетом на API для Python, что обеспечивает беспроблемную интеграцию с различными фреймворками машинного обучения, такими как PyTorch и TensorFlow, а также специализированными библиотеками, такими как vLLM и TRT-LLM.
Объединение запросов (Batching): Ray Serve поддерживает объединение запросов, что значительно повышает пропускную способность, особенно для моделей, способных обрабатывать несколько входов одновременно. Эта функция важна для оптимизации производительности в производственных средах.
Развертывание нескольких моделей: Пользователи могут развертывать несколько моделей из одного кластера Ray Server, что облегчает совместное использование ресурсов и управление различными моделями, к которым обращаются через API-запросы.
Управление ресурсами: Ray предоставляет тонкий контроль над распределением ресурсов (CPU, GPU, память) для каждой модели и её реплик. Это обеспечивает оптимизированное использование ресурсов, что важно для обработки высокозагруженных рабочих нагрузок.
Интеграция с ускорителями: Фреймворк поддерживает различные устройства-ускорители, такие как TPU и GPU, автоматически обнаруживая доступные ресурсы для оптимизации производительности без необходимости в пользовательских настройках.
vLLM: оптимизированный инференс
vLLM — это специализированный движок для инференса LLM, предоставляющий:
Paged Attention: Эта инновационная техника оптимизирует использование памяти при выполнении операций внимания, значительно повышая производительность и позволяя эффективно управлять ресурсами на различных аппаратных платформах.
Continuous Batching: vLLM поддерживает непрерывную пакетную обработку входящих запросов, что улучшает пропускную способность системы, позволяя обрабатывать несколько запросов одновременно, а не по одному.
Quantization Support: Библиотека предлагает различные методы квантования, включая GPTQ, AWQ, INT4, INT8 и FP8, которые помогают уменьшить размер модели и ускорить вывод без потери точности (или около без потери).
Streaming Outputs: Библиотека позволяет стримить ответы модели, что снижает задержку и улучшает пользовательский опыт.
Compatibility with Multiple Architectures: vLLM беспрепятственно интегрируется с популярными моделями из Hugging Face и поддерживает тензорный и pipeline параллелизм для распределенного вывода, что делает его достаточно универсальным.
Особенности конфигурации
В моем Homelab имеются 2 виртуальные машины с такими видеокартами:
- Основная нода: NVIDIA RTX 3090 (24GB VRAM)
- Воркер-нода: NVIDIA RTX 3080 Ti (12GB VRAM)
Перед запуском необходимо:
- Создать идентичные окружения. Я использую
pyenvиuv. - Модель должна находиться по одинаковому пути (например,
/root/gemma2).
Настройка окружения
Определите переменные окружения для указания сетевого интерфейса, обеспечивающего связность между узлами (для определения интерфейса можно использовать ip a):
export GLOO_SOCKET_IFNAME="eth0"
export NCCL_SOCKET_IFNAME="eth0"
Создайте виртуальное окружение и установите необходимые пакеты:
uv pip install "ray[default]"
uv pip install vllm==0.6.5
Запуск Ray на мастер-ноде
ray start --head \
--node-ip-address=192.168.1.166 \ # IP вашего сервера
--port=6379 \
--dashboard-port=8265 \
--dashboard-host=0.0.0.0 \
--num-gpus=1
Подключение воркер-ноды
ray start \
--address='192.168.1.166:6379' \
--num-gpus=1
Запуск vLLM на мастер-ноде
vllm serve /root/gemma2 \
--tensor-parallel-size 1 \
--pipeline-parallel-size 2 \
--host 0.0.0.0 \
--port 8000 \
--distributed-executor-backend ray \
--gpu-memory-utilization 0.6 \
--max-model-len 4096 \
--max-num-seqs 8 \
--max-num-batched-tokens 4096 \
--block-size 16 \
--use-v2-block-manager \
--num-gpu-blocks-override 512
Объяснение параметров запуска:
/root/gemma2: Путь к директории с моделью. Указывает, где находятся файлы модели.--tensor-parallel-size 1: Отключает тензорный параллелизм. Модель не разбивается на части для обработки на нескольких GPU по тензорам. В данном случае используется pipeline parallelism.--pipeline-parallel-size 2: Включает pipeline параллелизм и разбивает модель на 2 части для обработки на двух GPU. Первая часть обрабатывается на первом GPU, вторая - на втором.--host 0.0.0.0: API доступен со всех сетевых интерфейсов.--port 8000: Порт, на котором будет запущен API сервер.--distributed-executor-backend ray: Использует Ray для распределенных вычислений.--gpu-memory-utilization 0.6: Использует 60% доступной памяти GPU. Это помогает избежать ошибок нехватки памяти (OOM).--max-model-len 4096: Максимальная длина последовательности (prompt + generated text) в токенах.--max-num-seqs 8: Максимальное количество одновременных запросов (последовательностей), которые могут обрабатываться. Увеличивает параллелизм, но требует больше памяти.--max-num-batched-tokens 4096: Максимальное количество токенов, которые могут быть обработаны в одном батче. Влияет на производительность и потребление памяти.--block-size 16: Размер блока KV-кэша в GPU памяти. Меньший размер блока приводит к более эффективному использованию памяти, но может снизить производительность.--use-v2-block-manager: Использует улучшенный менеджер блоков памяти (v2), который более эффективно управляет памятью GPU.--num-gpu-blocks-override 512: Явно задает количество блоков KV-кэша на GPU. Переопределяет автоматический расчет и позволяет точно контролировать использование памяти. В данном случае,512 * 16 = 8192токенов могут быть закэшированы.
Эти параметры специально подобраны для обеспечения запуска модели на видеокартах с различным объемом памяти. По умолчанию vLLM может завершиться с ошибкой нехватки памяти (OOM), особенно на RTX 3080 Ti, где 12 ГБ видеопамяти недостаточно для размещения половины модели с большим контекстным окном. Это достаточно тонкая настройка, требующая дополнительного изучения.
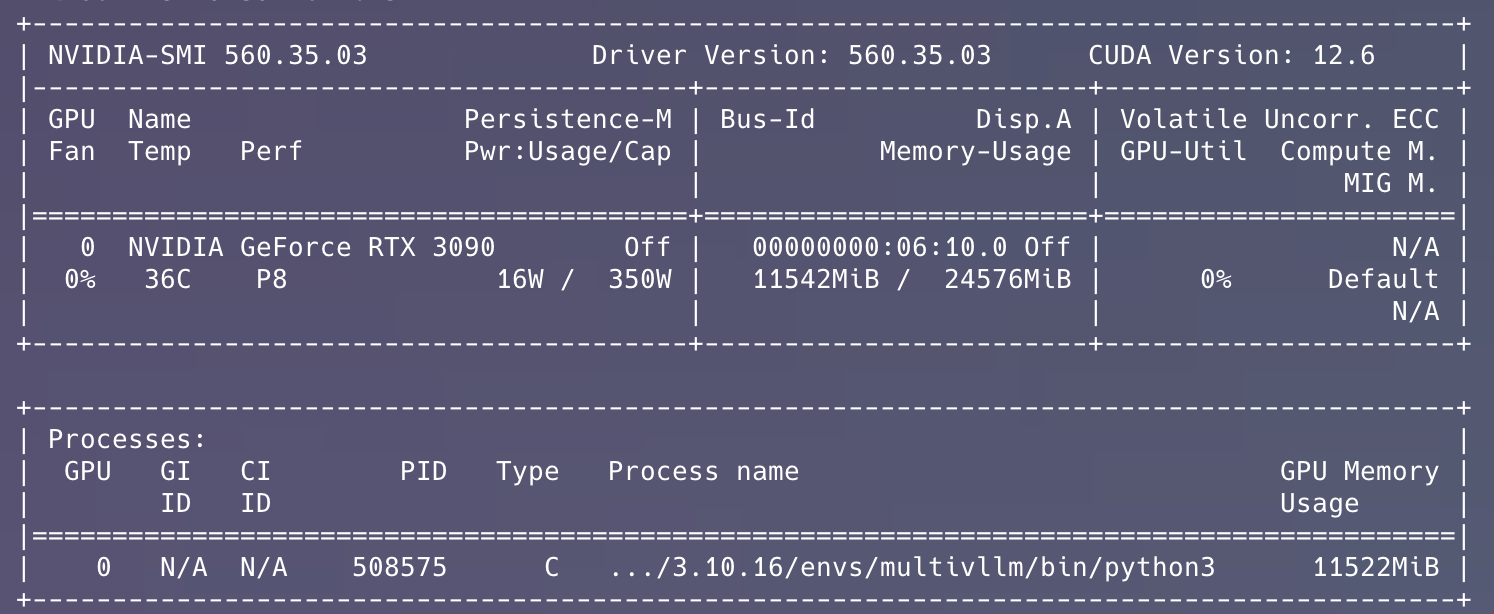
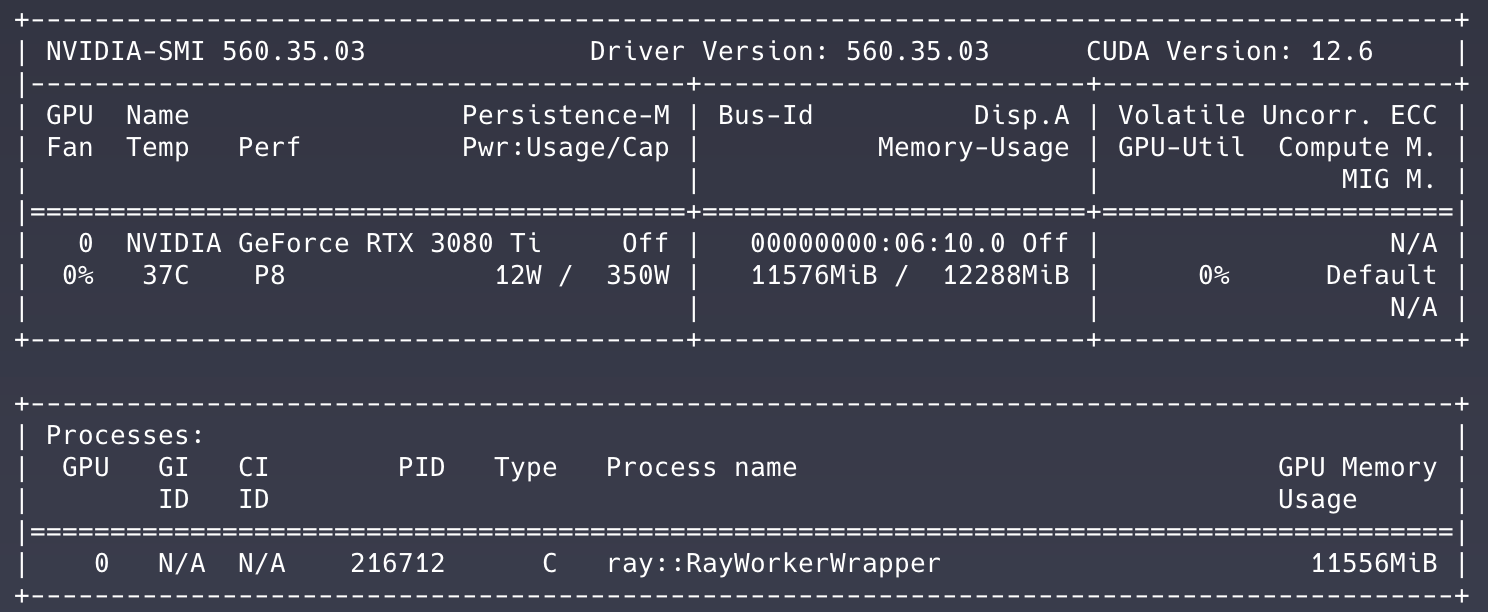
После загрузки модели вы можете через nvtop или nvidia-smi увидеть что модель действительно загружаена на обеих GPU.
Мастер-нода:
Воркер-нода:
Проверка работы модели
Чтобы проверить работоспособность модели, выполните стандартный запрос на мастер-ноде:
curl http://master-node-ip:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/root/gemma2",
"prompt": "Tell me a story",
"max_tokens": 1024,
"temperature": 0.7,
"stream": false
}'
Производительность модели существенно снижается при таком муве, однако это позволяет запускать модели, которые не помещаются в память одной видеокарты, в случаях когда нет возможности объединить GPU в одном физическом сервере (как в моем случае).
Хоть это и синтетический тест (по сути), так как Gemma 2 влезает в память моей RTX 3090, основной интерес был именно в том, чтобы запустить модель на двух видеокартах.
На этом завершаю статью. В дальнейшем планирую более детально изучить возможности Ray, так как этот фреймворк показался мне очень перспективным и интересным.