Оригинальная статья: December 2024
TL;DR
По мере увеличения сложности и размера моделей на основе трансформеров, растет и необходимость оптимизации скорости их вывода (inference), особенно в чат-приложениях, где пользователи ожидают мгновенных ответов.
Кэширование ключей и значений (Key-Value, KV) — это умный прием для достижения этой цели: во время вывода (inference) матрицы ключей и значений вычисляются для каждого сгенерированного токена. KV-кэширование сохраняет эти матрицы в памяти, так что при генерации последующих токенов мы вычисляем ключи и значения только для новых токенов, вместо того чтобы пересчитывать всё заново.
Ускорение вывода благодаря KV-кэшированию достигается за счет увеличения потребления памяти. Когда память становится узким местом, можно освободить часть ресурсов, упростив модель, пожертвовав при этом её точностью.
Реализация KV-кэширования в крупномасштабных производственных системах требует тщательного управления кэшем, включая выбор подходящей стратегии для инвалидации кэша и поиск возможностей для повторного использования кэша.
Архитектура трансформеров, без сомнения, является одним из самых значительных инноваций в современном глубоком обучении. Предложенная в знаменитой статье 2017 года “Attention Is All You Need”, она стала основным подходом для большинства задач, связанных с моделированием языка, включая все крупные языковые модели (Large Language Models, LLM), такие как семейство GPT, а также многие задачи компьютерного зрения.
С увеличением сложности и размера этих моделей растет и необходимость оптимизации скорости их вывода (inference), особенно в чат-приложениях, где пользователи ожидают мгновенных ответов. Кэширование ключей и значений (Key-Value, KV caching) — это clever trick, который позволяет достичь этой цели. Давайте разберем, как это работает и когда стоит его использовать.
Обзор архитектуры Transformer
Прежде чем мы углубимся в KV caching (кэширование ключей и значений), нам нужно сделать небольшое отступление и рассмотреть механизм внимания, используемый в трансформерах. Понимание того, как он работает, необходимо для того, чтобы заметить и оценить, как KV caching оптимизирует вывод трансформеров.
Мы сосредоточимся на авторегрессионных моделях, используемых для генерации текста. Эти так называемые декодерные модели включают в себя семейство GPT, Gemini, Claude или GitHub Copilot. Они обучаются на простой задаче: предсказание следующего токена в последовательности. Во время вывода модели предоставляется некоторый текст, и её задача — предсказать, как этот текст должен продолжаться.
С высоты птичьего полёта большинство трансформеров состоят из нескольких основных строительных блоков:
- Токенизатор, который разбивает входной текст на части, такие как слова или подсловы.
- Слой эмбеддингов, который преобразует полученные токены (и их относительные позиции в тексте) в векторы.
- Несколько базовых слоёв нейронной сети, включая dropout, layer normalization (нормализацию слоёв) и обычные feed-forward линейные слои.
Последний недостающий элемент из списка выше — это несколько более сложные модули self-attention.
Модуль self-attention, пожалуй, является единственным продвинутым элементом логики в архитектуре трансформера. Это краеугольный камень каждого трансформера, позволяющий ему фокусироваться на различных частях входной последовательности при генерации выходных данных. Именно этот механизм дает трансформерам возможность эффективно моделировать долгосрочные зависимости.
Давайте подробнее рассмотрим модуль self-attention.
Базовый модуль self-attention
Self-attention — это механизм, который позволяет модели “обращать внимание” на определённые части входной последовательности при генерации следующего токена. Например, при генерации предложения “She poured the coffee into the cup” (Она налила кофе в чашку) модель может уделить больше внимания словам “poured” (налила) и “coffee” (кофе), чтобы предсказать слово “into” (в) как следующее, поскольку эти слова предоставляют контекст для того, что, вероятно, последует дальше (в отличие от слов “she” (она) и “the”).
С математической точки зрения, цель self-attention заключается в преобразовании каждого входного элемента (embedded токена) в так называемый контекстный вектор, который объединяет информацию из всех входных данных в заданном тексте. Рассмотрим текст “She poured coffee” (Она налила кофе). Механизм внимания вычислит три контекстных вектора, по одному для каждого входного токена (предположим, что токены — это слова).
Для вычисления контекстных векторов self-attention рассчитывает три вида промежуточных векторов: запросы (queries), ключи (keys) и значения (values). На диаграмме ниже пошагово показано, как вычисляется контекстный вектор для второго слова — “poured” (налила):
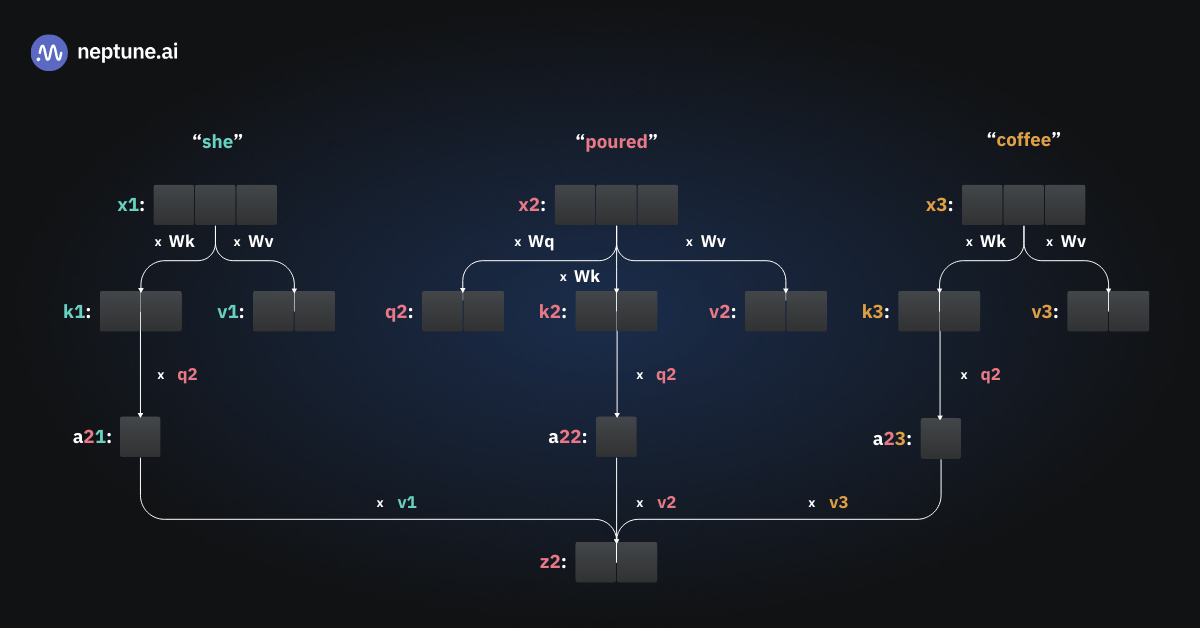
Диаграмма пошагово показывает, как вычисляется контекстный вектор для второго слова — “poured”. | Источник: Автор
Обозначим три токенизированных входа как x1, x2 и x3 соответственно. На диаграмме они изображены как векторы с тремя элементами, но на практике их длина может составлять сотни или тысячи элементов.
На первом этапе self-attention умножает каждый вход отдельно на две весовые матрицы, Wk и Wv. Вход, для которого в данный момент вычисляется контекстный вектор (в нашем случае x2), дополнительно умножается на третью весовую матрицу, Wq. Все три матрицы W — это обычные веса нейронной сети, инициализированные случайным образом и оптимизируемые в процессе обучения. Результатами этого этапа являются векторы ключей (k) и значений (v) для каждого входа, а также дополнительный вектор запроса (q) для обрабатываемого входа.
На втором этапе вектор ключа каждого входа умножается на вектор запроса обрабатываемого входа (в нашем случае q2). Затем результат нормализуется (не показано на диаграмме) для получения весов внимания. В нашем примере a21 — это вес внимания между входами “She” и “poured.”
Наконец, каждый вес внимания умножается на соответствующий ему вектор значения. Результаты затем суммируются для получения контекстного вектора z. В нашем примере контекстный вектор z2 соответствует входу x2, “poured.” Контекстные векторы являются выходными данными модуля self-attention.
Если вам проще читать код, чем диаграммы, взгляните на эту реализацию базового модуля self-attention от Себастьяна Рашки. Код является частью его книги «Build A Large Language Model (From Scratch)»:
import torch
class SelfAttention_v2(torch.nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.W_query = torch.nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = torch.nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = torch.nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
Код Себастьяна работает с матрицами: x в его методе forward() соответствует нашим векторам x1, x2 и x3, объединенным в матрицу с тремя строками. Это позволяет ему просто умножить x на W_key, чтобы получить ключи — матрицу, состоящую из трех строк (k1, k2 и k3 в нашем примере).
Важный вывод из этого краткого объяснения self-attention заключается в том, что на каждом этапе прямого прохода мы умножаем ключи на запросы, а затем на значения. Держите это в уме, продолжая чтение.
Продвинутые модули self-attention
Описанный выше вариант self-attention является его простейшей базовой формой. Сегодня крупнейшие LLM (языковые модели) обычно используют слегка модифицированные варианты, которые отличаются от базовой версии в трёх основных аспектах:
- Внимание является каузальным (causal).
- На веса внимания применяется dropout.
- Используется многоголовое внимание (multi-head attention).
Каузальное внимание означает, что модель должна учитывать только предыдущие токены в последовательности при предсказании следующего, что предотвращает возможность “заглядывать вперёд” на будущие слова. Возвращаясь к нашему примеру, “She poured coffee.”, когда модель получает слово “She” и пытается предсказать следующее (“poured” было бы правильным ответом), она не должна вычислять или иметь доступ к весам внимания между “coffee” и любым другим словом, поскольку слово “coffee” ещё не появилось в тексте. Каузальное внимание обычно реализуется путём маскирования “заглядывающей вперёд” части матрицы весов внимания нулями.
Далее, чтобы уменьшить переобучение во время обучения, к весам внимания часто применяется dropout. Это означает, что некоторые из них случайным образом обнуляются в каждом прямом проходе.
Наконец, базовое внимание можно назвать одноголовым (single-head), что означает наличие всего одного набора матриц Wk, Wq и Wv. Простой способ увеличить ёмкость модели — перейти к многоголовому вниманию. Это сводится к использованию нескольких наборов W-матриц и, как следствие, нескольких матриц запросов, ключей и значений, а также нескольких контекстных векторов для каждого входа.
Кроме того, некоторые трансформеры реализуют дополнительные модификации модуля внимания с целью повышения скорости или точности. Три популярных из них:
- Grouped-query attention: Вместо того чтобы рассматривать каждый входной токен по отдельности, токены группируются, что позволяет модели сосредотачиваться на связанных группах слов одновременно, что ускоряет обработку. Этот подход используется в Llama 3, Mixtral и Gemini.
- Paged attention: Внимание разбивается на «страницы» или фрагменты токенов, так что модель обрабатывает одну страницу за раз, что ускоряет работу с очень длинными последовательностями.
- Sliding-window attention: Модель учитывает только близлежащие токены в пределах фиксированного «окна» вокруг каждого токена, что позволяет ей сосредоточиться на локальном контексте без необходимости просматривать всю последовательность.
Все эти современные подходы к реализации самовнимания не меняют его основную предпосылку и фундаментальный механизм, на который оно опирается: всегда необходимо умножать ключи на запросы, а затем на значения. И, как оказывается, во время вывода (inference) эти умножения демонстрируют значительную неэффективность. Давайте разберемся, почему это происходит.
Что такое кэширование ключ-значение?
Во время вывода (inference) трансформеры генерируют один токен за раз. Когда мы передаем модели запрос для начала генерации, например, “She” (“Она”), она производит одно слово, например, “poured” (“налила”) (для упрощения предположим, что один токен соответствует одному слову). Затем мы можем передать модели “She poured” (“Она налила”), и она произведет слово “coffee” (“кофе”). Далее мы передаем “She poured coffee” (“Она налила кофе”) и получаем от модели токен конца последовательности, указывающий на то, что она считает генерацию завершенной.
Это означает, что мы выполнили прямое прохождение (forward pass) три раза, каждый раз умножая запросы на ключи для получения оценок внимания (то же самое относится к последующему умножению на значения).
При первом прямом прохождении был только один входной токен (“She”), что привело к созданию только одного вектора ключа и одного вектора запроса. Мы умножили их, чтобы получить оценку внимания q1k1.
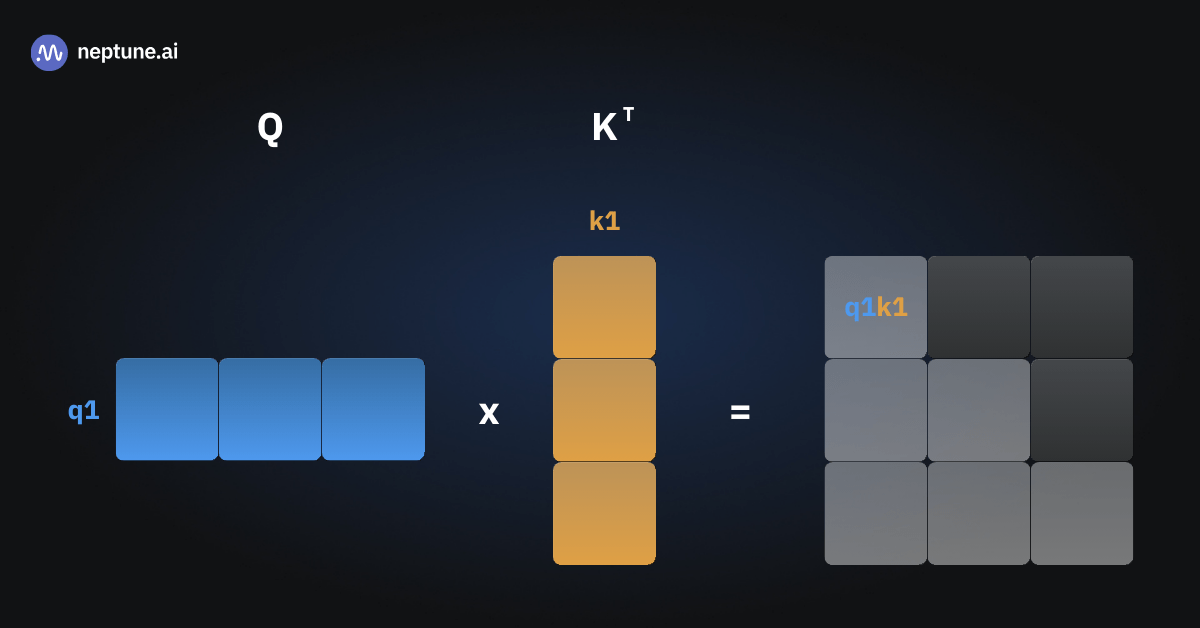
Затем мы передали модели “She poured” (“Она налила”). Теперь она видит два входных токена, поэтому вычисления внутри нашего модуля внимания выглядят следующим образом:
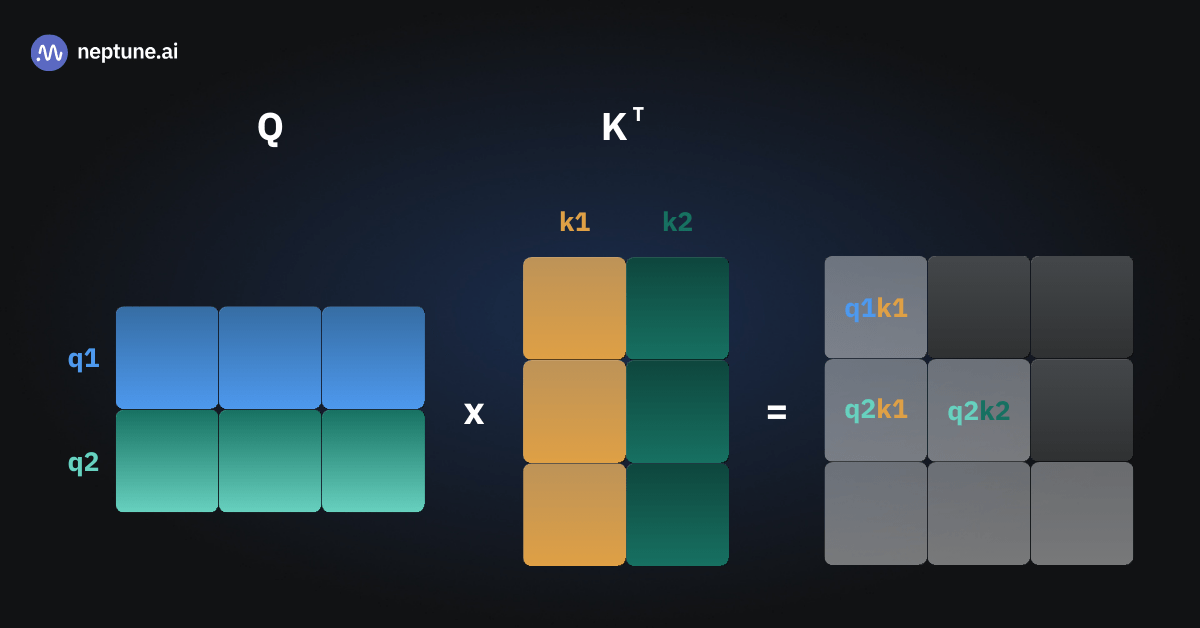
Мы выполнили умножение для вычисления трёх элементов, но q1k1 было вычислено напрасно — мы уже рассчитывали его ранее! Этот элемент q1k1 такой же, как и в предыдущем прямом проходе, потому что:
- q1 вычисляется как эмбеддинг входного слова (“She”), умноженный на матрицу Wq,
- k1 вычисляется как эмбеддинг входного слова (“She”), умноженный на матрицу Wk,
- И эмбеддинги, и весовые матрицы остаются постоянными во время инференса.
Обратите внимание на затенённые элементы в матрице оценок внимания: они замаскированы нулями для достижения причинного внимания (causal attention). Например, элемент в правом верхнем углу, где могло бы быть q1k3, не показывается модели, так как мы не знаем третье слово (и k3) в момент генерации второго слова.
Наконец, вот иллюстрация вычисления query-times-keys в нашем третьем прямом проходе.
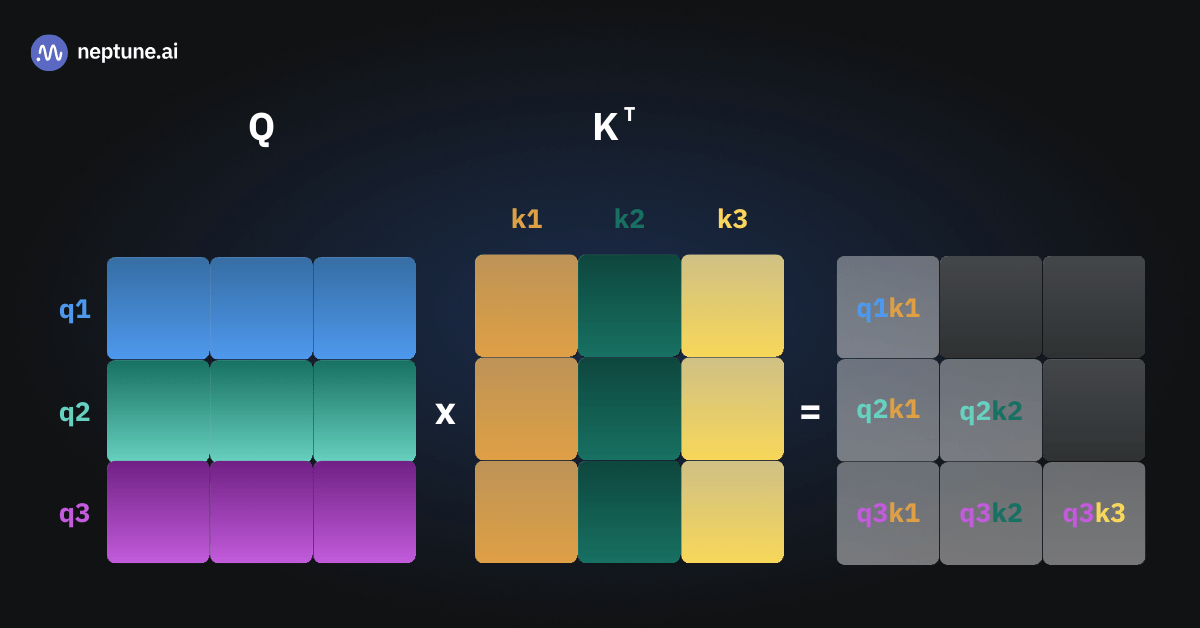
Мы прилагаем вычислительные усилия для расчёта шести значений, половину из которых мы уже знаем и не нуждаемся в их повторном вычислении!
Возможно, у вас уже есть догадка о том, что такое key-value caching (кэширование ключей и значений). Во время инференса, когда мы вычисляем матрицы ключей (K) и значений (V), мы сохраняем их элементы в кэше. Кэш — это вспомогательная память, из которой возможна высокоскоростная выборка. По мере генерации последующих токенов мы вычисляем ключи и значения только для новых токенов.
Например, вот как может выглядеть третий прямой проход (forward pass) с использованием кэширования:
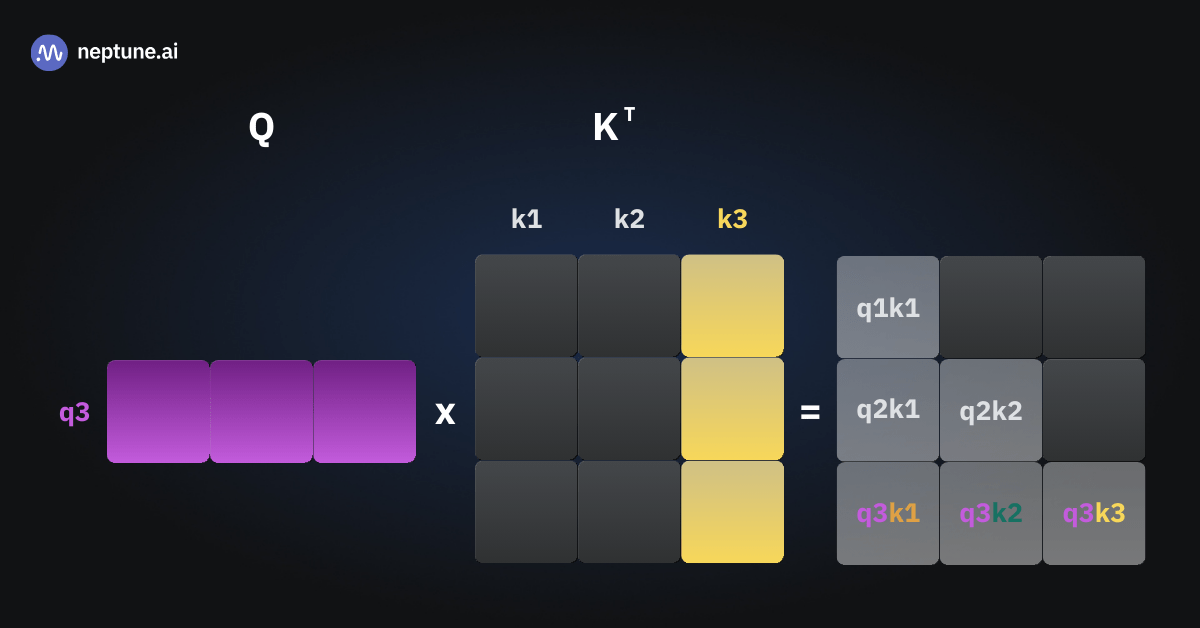
При обработке третьего токена нам не нужно пересчитывать attention scores для предыдущих токенов. Мы можем извлечь ключи и значения для первых двух токенов из кэша, тем самым сэкономив время вычислений.
Оценка влияния кэширования ключей и значений
Кэширование ключей и значений может значительно повлиять на время выполнения вывода (inference time). Величина этого влияния зависит от архитектуры модели. Чем больше вычислений можно закэшировать, тем выше потенциал для сокращения времени вывода.
Давайте проанализируем влияние K-V кэширования на время генерации, используя модель GPT-Neo-1.3B от EleutherAI, доступную на Hugging Face Hub.
Мы начнем с определения контекстного менеджера таймера для расчета времени генерации:
import time
class Timer:
def __enter__(self):
self._start = time.time()
return self
def __exit__(self, exc_type, exc_value, traceback):
self._end = time.time()
self.duration = self._end - self._start
def get_duration(self) -> float:
return self.duration
Далее мы загружаем модель из Hugging Face Hub, настраиваем токенизатор и определяем промт:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "EleutherAI/gpt-neo-1.3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
input_text = "Why is a pour-over the only acceptable way to drink coffee?"
Наконец, мы можем определить функцию для выполнения вывода модели:
def generate(use_cache):
input_ids = tokenizer.encode(
input_text,
return_tensors="pt").to(device),
)
output_ids = model.generate(
input_ids,
max_new_tokens=100,
use_cache=use_cache,
)
Обратите внимание на аргумент use_cache, который мы передаем в model.generate: он управляет использованием K-V кэширования.
С такой настройкой мы можем измерить среднее время генерации с использованием K-V кэширования и без него:
for use_cache in (False, True):
gen_times = []
for _ in range(10):
with Timer() as t:
generate(use_cache=use_cache)
gen_times += [t.duration]
print(f"Average inference time with use_cache={use_cache}: {np.round(np.mean(gen_times), 2)} seconds")
Я выполнил этот код на Google Colab с использованием бесплатного T4 GPU, используя torch==2.5.1+cu121 и transformers==4.46.2 на Python 3.10.12, и получил следующий результат:
Average inference time with use_cache=False: 9.28 seconds
Average inference time with use_cache=True: 3.19 seconds
Как видите, в данном случае ускорение за счет кэширования почти трехкратное.
Проблемы и компромиссы
Как это обычно бывает, бесплатного сыра не бывает. Ускорение генерации, которое мы только что рассмотрели, может быть достигнуто только за счет увеличения использования памяти, и оно требует внимательного управления в производственных системах.
Компромисс между задержкой и памятью
Хранение данных в кэше занимает место в памяти. Системы с ограниченными ресурсами памяти могут столкнуться с трудностями при попытке разместить этот дополнительный объем памяти, что может привести к ошибкам нехватки памяти (out-of-memory). Это особенно актуально, когда необходимо обрабатывать длинные входные данные, так как объем памяти, необходимый для кэша, растет линейно с увеличением длины входных данных.
Другой аспект, который следует учитывать, заключается в том, что дополнительная память, потребляемая кэшем, недоступна для хранения пакетов данных. В результате может потребоваться уменьшить размер пакета, чтобы он оставался в пределах доступной памяти, что снижает пропускную способность системы.
Если потребление памяти кэшем становится проблемой, можно пожертвовать частью точности модели в обмен на дополнительную память. В частности, можно усечь последовательности, сократить количество attention-голов или применить квантование модели:
Усечение последовательностей (Sequence truncation) означает ограничение максимальной длины входной последовательности, тем самым ограничивая размер кэша за счет потери долгосрочного контекста. В задачах, где этот длинный контекст важен, точность модели может снизиться.
Сокращение количества слоев или attention-голов — это еще одна стратегия для освобождения памяти, которая уменьшает как размер модели, так и требования к памяти для кэша. Однако уменьшение сложности модели может повлиять на ее точность.
Наконец, существует квантование, которое предполагает использование типов данных с более низкой точностью (например, float16 вместо float32) для кэширования с целью уменьшения использования памяти. Опять же, это может негативно сказаться на точности модели.
В итоге, более высокая скорость генерации, обеспечиваемая K-V кэшированием, достигается за счет увеличения использования памяти. Если памяти достаточно, это не проблема. Однако если память становится узким местом, можно освободить ее, упрощая модель различными способами, тем самым переходя от компромисса между задержкой и памятью к компромиссу между задержкой и точностью.
Управление KV-кэшем в производственных системах
В крупномасштабных производственных системах с большим количеством пользователей KV-кэш необходимо правильно управлять, чтобы обеспечить стабильное и надежное время отклика, предотвращая при этом чрезмерное потребление памяти. Два наиболее важных аспекта этого — инвалидация кэша (когда его очищать) и повторное использование кэша (как использовать один и тот же кэш несколько раз).
Инвалидация кэша
Три наиболее популярные стратегии инвалидации кэша — это очистка на основе сессии, инвалидация по времени жизни (TTL) и подходы, основанные на контекстной релевантности. Рассмотрим их по порядку.
Самая базовая стратегия инвалидации кэша — это очистка на основе сессии. Мы просто очищаем кэш в конце сессии пользователя или диалога с моделью. Эта простая стратегия идеально подходит для приложений, где диалоги короткие и независимы друг от друга.
Представьте приложение чат-бота для службы поддержки, в котором каждая сессия пользователя обычно представляет собой отдельный диалог, где пользователь ищет помощь по конкретным вопросам. В этом контексте содержимое кэша вряд ли понадобится снова. Очистка KV-кэша после завершения чата пользователем или по истечении времени ожидания из-за бездействия — это хороший выбор, который освобождает память для обработки новых пользователей.
Однако в ситуациях, когда отдельные сессии длительные, существуют более подходящие решения, чем очистка на основе сессии. При инвалидации по времени жизни (TTL) содержимое кэша автоматически очищается через определенный период. Эта стратегия хорошо подходит, когда релевантность закэшированных данных предсказуемо снижается со временем.
Рассмотрим приложение-агрегатор новостей, которое предоставляет обновления в реальном времени. Закэшированные ключи и значения могут быть актуальны только до тех пор, пока новость остается горячей. Реализация политики TTL, при которой закэшированные записи истекают, скажем, через день, гарантирует, что ответы на похожие запросы о свежих событиях будут генерироваться быстро, а старые новости не будут занимать память.
Наконец, самая сложная из трех популярных стратегий инвалидации кэша основана на контекстной релевантности. Здесь мы очищаем содержимое кэша, как только оно становится нерелевантным текущему контексту или взаимодействию с пользователем. Эта стратегия идеальна, когда приложение обрабатывает разнообразные задачи или темы в рамках одной сессии, и предыдущий контекст не приносит пользы новому.
Представьте помощник для программирования, который работает как плагин для IDE. Пока пользователь работает с определенным набором файлов, кэш должен сохраняться. Однако, как только он переключается на другую кодовую базу, предыдущие ключи и значения становятся нерелевантными и могут быть удалены для освобождения памяти. Тем не менее, подходы, основанные на контекстной релевантности, могут быть сложными в реализации, так как требуют точного определения момента или события, когда происходит смена контекста.
Повторное использование кэша
Еще одним важным аспектом управления кэшем является его повторное использование. В некоторых случаях один раз сгенерированный кэш может быть использован снова для ускорения генерации и экономии памяти, избегая хранения одних и тех же данных несколько раз в разных экземплярах кэша пользователей.
Возможности повторного использования кэша обычно возникают, когда существует общий контекст и/или желателен “теплый старт”.
В сценариях, где несколько запросов имеют общий контекст, можно повторно использовать кэш для этой общей части. На платформах электронной коммерции определенные продукты могут иметь стандартные описания или характеристики, которые часто запрашиваются несколькими клиентами. Это может включать детали продукта («55-дюймовый 4K Ultra HD Smart LED TV»), информацию о гарантии («Поставляется с 2-летней гарантией производителя, покрывающей детали и работу.») или инструкции для клиентов («Для лучших результатов установите телевизор с использованием совместимого настенного кронштейна, продается отдельно.»). Кэшируя пары ключ-значение для этих общих описаний продуктов, чат-бот службы поддержки клиентов будет быстрее генерировать ответы на часто задаваемые вопросы.
Аналогично, можно предварительно вычислить и закэшировать начальные пары ключ-значение для часто используемых запросов или подсказок. Рассмотрим голосовое приложение виртуального помощника. Пользователи часто начинают взаимодействие с фраз вроде «Какая сегодня погода?» или «Установи таймер на 10 минут». Помощник может отвечать быстрее, предварительно вычисляя и кэшируя пары ключ-значение для этих часто используемых запросов.
Заключение
Кэширование пар ключ-значение (K-V) — это техника в моделях трансформеров, где key и value-матрицы из предыдущих шагов сохраняются и повторно используются при генерации последующих токенов. Это позволяет сократить избыточные вычисления и ускорить время вывода. Однако такое ускорение достигается за счет увеличения потребления памяти. Когда память становится узким местом, можно освободить часть памяти, упростив модель, пожертвовав при этом ее точностью. Реализация K-V кэширования в крупномасштабных производственных системах требует тщательного управления кэшем, включая выбор стратегии для инвалидации кэша и изучение возможностей его повторного использования.