Оригинальная статья: MLOps Principles
Перевод: January 2025
Принципы MLOps
В связи с растущим внедрением технологий машинного обучения и искусственного интеллекта в программные продукты и сервисы, возникает необходимость в установлении передовых практик и инструментов для тестирования, развертывания, управления и мониторинга ML-моделей в промышленной эксплуатации. MLOps позволяет нам минимизировать "технический долг" в приложениях машинного обучения.
Согласно определению SIG MLOps, "оптимальный подход к MLOps предполагает, что компоненты машинного обучения обрабатываются систематически и наравне с другими программными компонентами в среде CI/CD. Модели машинного обучения могут быть развернуты совместно с сервисами, которые их обслуживают и потребляют, как часть единого процесса релиза." Стандартизация этих практик направлена на ускорение внедрения ML/AI в программные системы и оптимизацию процесса разработки интеллектуального программного обеспечения. В дальнейшем мы рассмотрим ключевые концепции MLOps, включая итеративно-инкрементальную разработку (Iterative-Incremental Development), автоматизацию (Automation), непрерывное развертывание (Continuous Deployment), версионирование (Versioning), тестирование (Testing), воспроизводимость (Reproducibility) и мониторинг (Monitoring).
Итеративно-инкрементальный процесс в MLOps
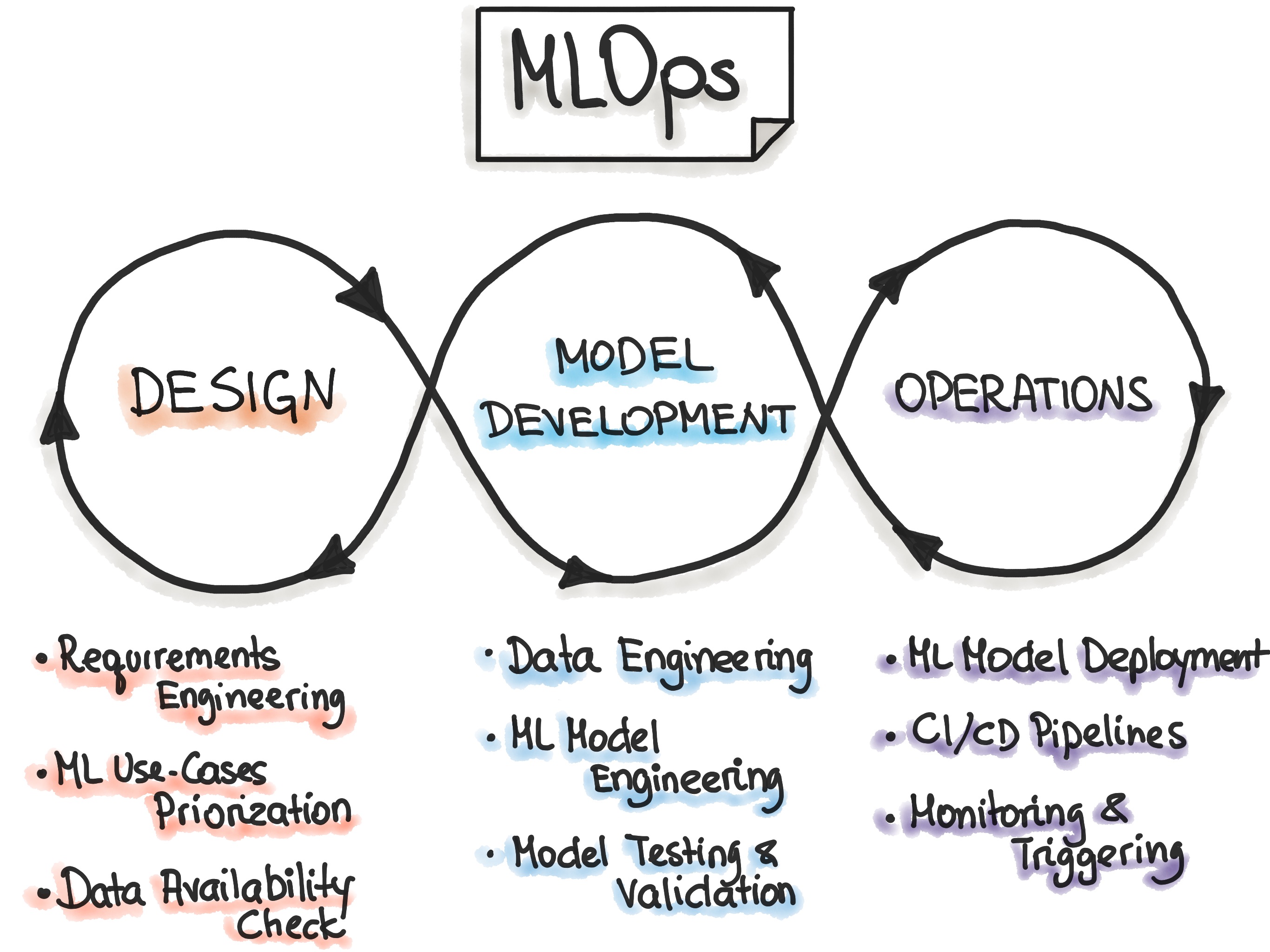
Процесс MLOps состоит из трех ключевых фаз: "Проектирование ML-приложения", "ML-экспериментирование и разработка" и "ML-операции".
Первая фаза - проектирование - включает в себя анализ бизнес-требований, исследование данных и проектирование ML-системы. На этом этапе мы определяем целевую аудиторию, разрабатываем концепцию решения на основе машинного обучения и оцениваем перспективы развития проекта. Как правило, решаются две основные категории задач: повышение эффективности работы пользователей либо улучшение интерактивности приложения.
В начале работы мы выявляем потенциальные сценарии применения ML (use cases) и определяем их приоритетность. Рекомендуется работать только с одним сценарием за раз. Также на этапе проектирования проводится анализ доступных данных для обучения модели и формулируются функциональные и нефункциональные требования. На основе этих требований разрабатывается архитектура ML-приложения, определяется стратегия его обслуживания и создается набор тестов для будущей модели.
Вторая фаза - "ML-экспериментирование и разработка" - направлена на проверку применимости машинного обучения путем создания прототипа модели (Proof-of-Concept). В рамках этой фазы мы итеративно выполняем такие задачи как выбор и настройка ML-алгоритма, подготовка данных и разработка модели. Главная цель - создать стабильную и качественную ML-модель, готовую к промышленной эксплуатации.
Третья фаза - "ML Operations" - фокусируется на внедрении разработанной ML-модели в производственную среду с использованием проверенных практик DevOps: тестирования, версионирования, непрерывной поставки (continuous delivery) и мониторинга.
Все три фазы тесно взаимосвязаны и оказывают взаимное влияние друг на друга. Например, архитектурные решения, принятые на этапе проектирования, определяют ход экспериментов и в итоге влияют на способы развертывания системы на этапе эксплуатации.
Автоматизация
Уровень автоматизации процессов работы с данными, ML-моделями и кодом определяет зрелость ML-системы. Чем выше уровень автоматизации, тем быстрее происходит обучение новых моделей. Основная задача MLOps-команды - автоматизировать развертывание ML-моделей, будь то интеграция в основную систему или выделение в отдельный сервисный компонент. Это подразумевает автоматизацию всех этапов ML-процесса без необходимости ручного вмешательства. Запуск автоматического обучения и развертывания моделей может происходить по различным триггерам: календарным событиям, системным сообщениям, событиям мониторинга, а также при изменениях в данных, коде обучения или коде приложения.
Автоматизированное тестирование позволяет выявлять проблемы на ранних стадиях, что дает возможность оперативно исправлять ошибки и учиться на них.
В MLOps выделяют три уровня автоматизации - от базового с ручным обучением и развертыванием до полностью автоматического выполнения ML и CI/CD пайплайнов:
-
Ручной процесс. Это начальный уровень внедрения ML, типичный для data science проектов. Данный этап носит экспериментальный и итеративный характер. Все шаги в каждом пайплайне (подготовка и валидация данных, обучение и тестирование модели) выполняются вручную. Обычно на этом этапе используются инструменты быстрой разработки (RAD), такие как Jupyter Notebooks.
-
Автоматизация ML-пайплайна. На этом уровне процесс обучения модели автоматизируется. Вводится концепция непрерывного обучения: при появлении новых данных автоматически запускается процесс переобучения модели. Также автоматизируются этапы валидации данных и проверки качества модели.
-
Автоматизация CI/CD-пайплайна. На финальном уровне внедряется полноценная CI/CD-система для быстрого и надежного развертывания ML-моделей в production-среду. Ключевое отличие от предыдущего уровня в том, что теперь автоматически выполняются сборка, тестирование и развертывание всех компонентов: данных, ML-модели и пайплайна обучения.
На следующем рисунке представлена схема автоматизированного ML-пайплайна с интегрированными CI/CD-процедурами:
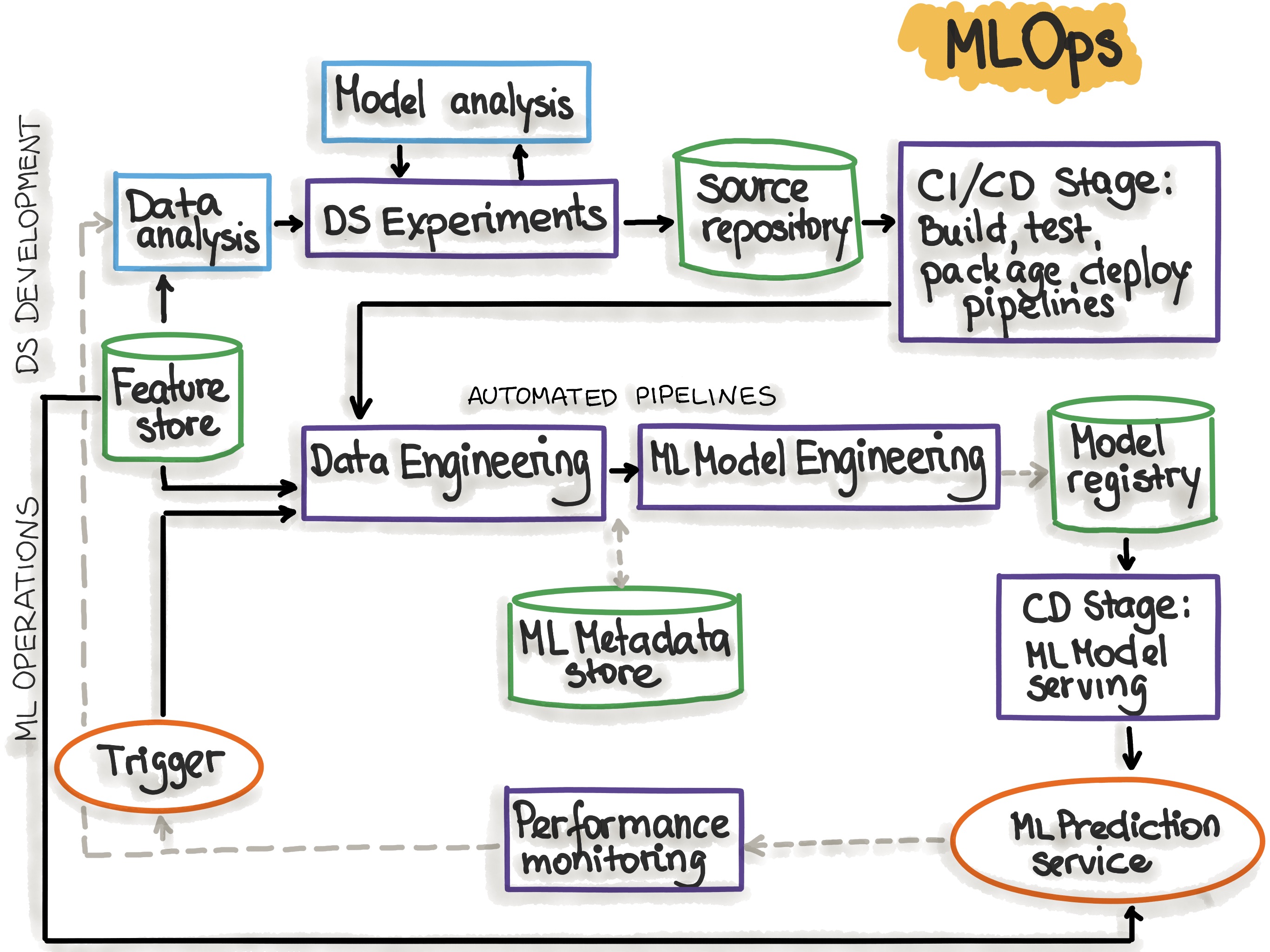
Этапы MLOps, отражающие процесс автоматизации ML-пайплайна, представлены в следующей таблице:
| Этап MLOps | Результат выполнения этапа |
|---|---|
| Разработка и экспериментирование (ML-алгоритмы, создание новых ML-моделей) | Исходный код для пайплайнов, включающий: извлечение и валидацию данных, их подготовку, обучение модели, оценку и тестирование |
| Непрерывная интеграция пайплайна (Pipeline CI) | Готовые к развертыванию компоненты пайплайна в виде пакетов и исполняемых файлов |
| Непрерывная поставка пайплайна (Pipeline CD) | Развернутый в целевой среде пайплайн с обновленной реализацией модели |
| Автоматическое выполнение | Обученная модель, сохраненная в Model Registry (запуск по расписанию или триггеру) |
| Непрерывная поставка модели | Развернутый сервис предсказаний (например, модель, доступная через REST API) |
| Мониторинг | Метрики производительности модели на реальных данных, запускающие новый цикл обучения или экспериментов |
Для эффективной работы MLOps-системы необходимо настроить следующие ключевые компоненты:
| Компонент MLOps | Описание |
|---|---|
| Система контроля версий | Управление версиями кода, данных и артефактов ML-модели |
| Сервисы тестирования и сборки | CI-инструменты для контроля качества ML-артефактов и создания исполняемых пакетов |
| Сервисы развертывания | CD-инструменты для автоматизированного развертывания пайплайнов |
| Реестр моделей (Model Registry) | Централизованное хранилище обученных ML-моделей |
| Хранилище признаков (Feature Store) | Система для подготовки и хранения признаков, используемых при обучении и работе модели |
| Хранилище метаданных | Система для отслеживания параметров обучения, метрик и результатов экспериментов |
| Оркестратор ML-пайплайнов | Система для автоматизации и управления ML-экспериментами |
Дополнительную информацию можно найти в статье "MLOps: Continuous delivery and automation pipelines in machine learning"
Continuous X
Для понимания процесса развертывания моделей (Model deployment) важно сначала определить понятие "ML-активов" (ML assets). К ним относятся: сама ML-модель, её параметры и гиперпараметры, скрипты обучения, а также тренировочные и тестовые наборы данных. При работе с ML-активами необходимо учитывать их идентификацию, составные компоненты, версионирование и зависимости. ML-активы могут быть развернуты как микросервисы или как часть инфраструктуры. Для обеспечения их стабильной работы сервис развертывания предоставляет функции оркестрации, логирования, мониторинга и оповещений.
MLOps представляет собой культуру машинного обучения, основанную на следующих ключевых практиках:
- Непрерывная интеграция (Continuous Integration, CI) - помимо стандартного тестирования и валидации кода, включает проверку качества данных и моделей.
- Непрерывная поставка (Continuous Delivery, CD) - обеспечивает автоматизированное развертывание пайплайна обучения и сервиса предсказаний ML-модели.
- Непрерывное обучение (Continuous Training, CT) - уникальная особенность ML-систем, позволяющая автоматически переобучать и обновлять модели.
- Непрерывный мониторинг (Continuous Monitoring, CM) - отслеживает качество входных данных и эффективность модели в production-среде, увязывая технические метрики с бизнес-показателями.
Версионирование
Цель версионирования - обеспечить полноценное управление версиями всех компонентов ML-системы: скриптов обучения, моделей и наборов данных, интегрируя их в DevOps-процессы с помощью систем контроля версий. Согласно SIG MLOps, существует ряд важных причин, по которым необходимо отслеживать изменения ML-моделей и данных:
- Переобучение моделей на новых данных
- Обновление подходов к обучению моделей
- Внедрение механизмов самообучения
- Деградация качества моделей со временем
- Развертывание моделей в новых приложениях
- Защита от атак и необходимость пересмотра моделей
- Возможность быстрого отката к предыдущим стабильным версиям
- Соответствие корпоративным и государственным требованиям аудита ML-моделей и данных
- Распределенное хранение данных в различных системах
- Ограничения на хранение данных в определенных юрисдикциях
- Особенности систем хранения данных
- Вопросы прав собственности на данные
Следуя лучшим практикам разработки надежного программного обеспечения, каждая спецификация ML-модели (код, создающий модель) должна проходить процедуру проверки кода. Более того, все спецификации ML-моделей необходимо версионировать в системе контроля версий для обеспечения проверяемости и воспроизводимости процесса обучения.
Дополнительная информация: Подробнее об управлении ML-моделями можно прочитать в статье Model Management Frameworks
Отслеживание экспериментов
Разработка систем машинного обучения представляет собой итеративный исследовательский процесс, существенно отличающийся от традиционной разработки программного обеспечения. В ML-проектах часто проводятся параллельные эксперименты по обучению различных моделей, и только после тщательного анализа результатов принимается решение о том, какая из моделей будет внедрена в производственную среду.
Типичный процесс экспериментов в ML-разработке можно организовать следующим образом: для каждого эксперимента создается отдельная ветка в системе контроля версий Git. В каждой ветке проводится обучение модели с определенными параметрами и конфигурацией. После обучения все модели сравниваются по заранее выбранным метрикам качества, и лучшая модель отбирается для дальнейшего использования. Такой подход к организации экспериментов эффективно реализуется с помощью инструмента DVC - открытой системы контроля версий, расширяющей возможности Git для проектов машинного обучения. Еще одним популярным решением является платформа Weights and Biases (wandb), которая обеспечивает автоматическое отслеживание гиперпараметров и метрик в ходе экспериментов.
Тестирование
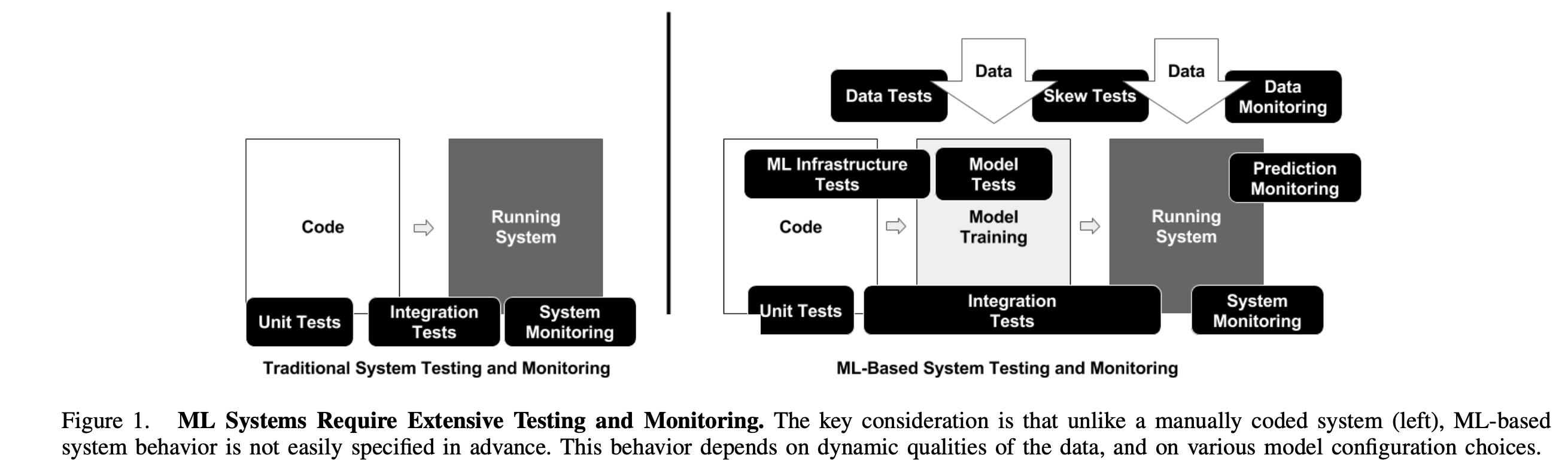
Полный конвейер разработки ML-системы включает три основных компонента: конвейер данных (data pipeline), конвейер ML-модели (ML model pipeline) и конвейер приложения (application pipeline). В соответствии с этой структурой выделяются три ключевые области тестирования: тестирование данных и признаков, тестирование ML-моделей и тестирование ML-инфраструктуры.
Тестирование данных и признаков
-
Валидация данных: Автоматическая проверка схемы и допустимых значений данных и признаков.
- Действие: Создайте схему данных на основе статистического анализа обучающей выборки. Эта схема будет служить спецификацией или семантическим описанием входных данных как для этапа обучения, так и для этапа вывода.
-
Оценка значимости признаков для определения их прогностической ценности.
- Действие: Проведите корреляционный анализ признаков.
- Действие: Постройте модель с использованием минимального набора признаков.
- Действие: Примените метод исключения признаков "leave-one-out" для обучения различных версий модели.
- Оцените влияние каждого нового признака на задержку вывода и потребление памяти, сопоставляя эти затраты с улучшением качества предсказаний.
- Своевременно удаляйте неиспользуемые признаки из системы, документируя все изменения.
-
Обеспечение соответствия конвейеров данных и признаков нормативным требованиям (например, GDPR). Это соответствие должно автоматически проверяться как в среде разработки, так и в промышленной эксплуатации.
-
Код генерации признаков должен быть покрыт модульными тестами для своевременного выявления ошибок.
Тестирование для обеспечения надежности моделей
Для выявления специфичных для машинного обучения ошибок необходимо внедрить специализированные тестовые процедуры.
-
Тестирование процесса обучения моделей должно проверять соответствие принимаемых решений бизнес-целям. Это означает, что технические метрики качества модели (среднеквадратичная ошибка, логистическая функция потерь и др.) должны коррелировать с бизнес-показателями (выручка, вовлеченность пользователей и т.д.)
-
Тестирование актуальности модели. Модель считается устаревшей, если она обучена на неактуальных данных или не соответствует текущим бизнес-требованиям. Устаревшие модели могут существенно снижать качество предсказаний.
- Действие: Провести A/B-тестирование с моделями разного "возраста". Построить зависимость качества предсказаний от времени использования модели, чтобы определить оптимальную частоту переобучения.
-
Оценка целесообразности использования сложных моделей.
- Действие: Сравнивать производительность сложной модели с базовой (например, линейной регрессии с нейронной сетью).
-
Валидация эффективности модели.
- Рекомендуется разделять команды и процессы сбора обучающих и тестовых данных во избежание переноса методологических ошибок (источник).
- Действие: Использовать отдельный тестовый набор данных, не задействованный при обучении и валидации, только для финальной оценки качества.
-
Тестирование модели на предмет справедливости и предвзятости.
- Действие: Расширить набор данных, включив недостаточно представленные категории.
- Действие: Проверить входные признаки на наличие корреляции с защищенными характеристиками пользователей.
- Дополнительно: "Методы сэмплирования для работы с несбалансированными данными"
-
Стандартное модульное тестирование всех компонентов: кода подготовки признаков, обучения модели и процедур тестирования.
-
Тестирование системы управления моделями (раздел в разработке)
Тестирование ML-инфраструктуры
- Процесс обучения ML-моделей должен быть воспроизводимым - при использовании одних и тех же данных должны получаться идентичные модели.
- Сложность дифференциального тестирования ML-моделей обусловлена невыпуклостью алгоритмов машинного обучения, генерацией случайных чисел и особенностями распределенного обучения.
- Действие: выявить и минимизировать недетерминированные компоненты в процессе обучения модели.
- Тестирование ML API и проведение нагрузочных испытаний.
- Действие: Разработать модульные тесты с генерацией случайных входных данных и проверкой одного шага оптимизации.
- Действие: Внедрить тесты на отказоустойчивость, проверяющие корректное восстановление модели из контрольных точек после сбоев в процессе обучения.
- Проверка алгоритмической корректности.
- Действие: Создать модульные тесты, проверяющие уменьшение функции потерь на нескольких итерациях обучения, без необходимости полного обучения модели.
- Не рекомендуется: Использовать дифференциальное тестирование с ранее обученными моделями из-за сложности поддержки таких тестов.
- Интеграционное тестирование всего ML-конвейера.
- Действие: Разработать автоматизированный тест для регулярной проверки полного цикла обучения - от подготовки данных до получения работающей модели.
- Все интеграционные тесты должны быть успешно пройдены перед развертыванием модели в производственной среде.
- Валидация ML-модели перед внедрением.
- Действие: Установить пороговые значения и отслеживать постепенное снижение качества модели на валидационном наборе данных.
- Действие: Определить критические пороги для выявления резкого падения производительности в новых версиях модели.
- Поэтапное тестирование ML-моделей перед полным развертыванием (canary-тестирование).
- Действие: Проверить корректность загрузки модели и точность предсказаний на реальных данных в производственной среде.
- Проверка идентичности результатов в средах обучения и эксплуатации.
- Действие: Сравнить производительность на отложенных данных и данных "следующего дня". Значительные расхождения могут указывать на проблемы с временными признаками.
- Действие: Обеспечить идентичность предсказаний для одних и тех же входных данных в обеих средах. Любые различия свидетельствуют о технических ошибках в реализации.
Мониторинг
После развертывания ML-модели необходимо организовать ее непрерывный мониторинг для обеспечения корректной работы. Ниже приведен чек-лист мониторинга моделей в производственной среде, основанный на работе "The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction" (E.Breck и др., 2017):
- Отслеживание изменений зависимостей во всем конвейере с системой оповещений:
- Изменения в версиях данных
- Изменения в исходных системах
- Обновления зависимостей
- Контроль инвариантов входных данных при обучении и выводе: система должна оповещать, если данные не соответствуют схеме, определенной на этапе обучения.
- Действие: настройка оптимальных пороговых значений для предотвращения ложных срабатываний.
- Проверка идентичности вычисления признаков при обучении и выводе.
- Поскольку генерация признаков может происходить в разных средах, критически важно обеспечить логическую идентичность этих процессов.
- Действие: (1) Логирование выборки данных при выводе. (2) Сравнение статистических показателей (минимум, максимум, среднее, процент пропущенных значений и т.д.) для признаков на этапах обучения и вывода.
- Контроль численной стабильности модели.
- Действие: настройка оповещений при появлении NaN или бесконечных значений.
- Мониторинг производительности ML-системы с отслеживанием как резких, так и постепенных ухудшений.
- Действие: измерение производительности всех компонентов с установленными пороговыми значениями.
- Действие: сбор метрик использования ресурсов (память GPU, сетевой трафик, дисковое пространство) для оценки облачных затрат.
- Отслеживание актуальности системы в production:
- Измерение "возраста" модели, так как устаревшие модели склонны к деградации.
- Действие: разработка стратегии мониторинга до запуска в production.
- Контроль процессов генерации признаков:
- Действие: регулярное обновление признаков.
- Мониторинг качества предсказаний модели на рабочих данных:
- Отслеживание как резких падений, так и постепенной деградации качества.
- Действие: измерение статистического смещения в предсказаниях.
- Действие: при наличии быстрой обратной связи - оценка качества предсказаний в реальном времени.
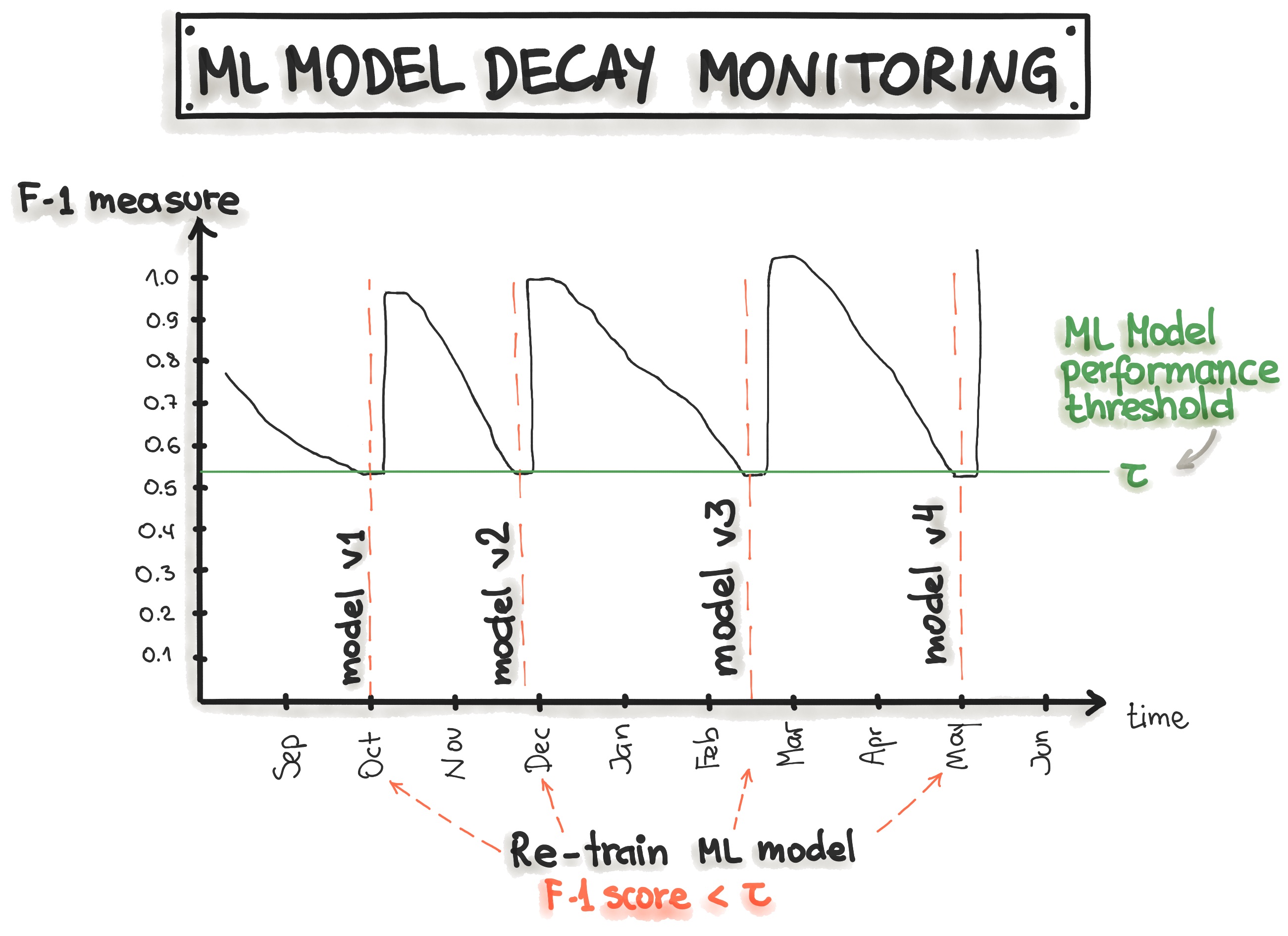
На рисунке ниже показан пример мониторинга модели через отслеживание метрик precision, recall и F1-score во времени. При снижении этих показателей запускается процесс переобучения модели для восстановления ее качества.
Система оценки ML Test Score
ML Test Score - это метрика, которая позволяет оценить степень готовности ML-системы к промышленному использованию. Расчет итогового показателя ML Test Score производится по следующим правилам:
- Если тест выполняется вручную, а его результаты документируются и распространяются среди команды - присваивается 0.5 балла.
- Если тест выполняется автоматически на регулярной основе - присваивается 1 балл.
- Баллы суммируются отдельно по каждой из четырех категорий тестов:
- Тесты данных (Data Tests)
- Тесты моделей (Model Tests)
- Тесты ML-инфраструктуры (ML Infrastructure Tests)
- Тесты мониторинга (Monitoring Tests)
- Итоговый ML Test Score определяется как минимальное значение среди сумм баллов по каждой категории.
После расчета ML Test Score можно сделать вывод о степени готовности ML-системы к промышленной эксплуатации. Интерпретация результатов приведена в таблице ниже:
| Баллы | Описание |
|---|---|
| 0 | Система находится на уровне исследовательского проекта и не готова к промышленной эксплуатации |
| (0,1] | Присутствует минимальное тестирование, но система имеет высокие риски с точки зрения надежности |
| (1,2] | Выполнена базовая подготовка к промышленной эксплуатации, однако требуются дополнительные доработки |
| (2,3] | Система имеет достаточный уровень тестирования, но есть потенциал для дальнейшей автоматизации процессов |
| (3,5] | Система демонстрирует высокий уровень автоматизации тестирования и мониторинга |
| >5 | Система достигла максимального уровня автоматизации тестирования и мониторинга |
Воспроизводимость
Воспроизводимость в машинном обучении означает, что при одинаковых входных данных каждый этап обработки данных, обучения и развертывания модели должен давать идентичные результаты.
| Этап | Проблемы | Обеспечение воспроизводимости |
|---|---|---|
| Сбор данных | Невозможность воспроизвести процесс генерации обучающих данных (из-за постоянных изменений в БД или случайной выборки) | 1) Создание резервных копий данных. 2) Сохранение снэпшотов наборов данных (например, в облачном хранилище). 3) Проектирование источников данных с метками времени для возможности получения среза данных на любой момент. 4) Версионирование данных. |
| Подготовка признаков | 1) Заполнение пропусков случайными или средними значениями. 2) Удаление наблюдений по заданному проценту. 3) Недетерминированные методы извлечения признаков. | 1) Код генерации признаков должен быть под контролем версий. 2) Необходима воспроизводимость предыдущего этапа сбора данных. |
| Обучение и сборка модели | Недетерминированность процесса | 1) Обеспечение постоянного порядка признаков. 2) Документирование и автоматизация преобразований признаков (например, нормализации). 3) Документирование и автоматизация выбора гиперпараметров. 4) Для ансамблевых методов: документирование и автоматизация процесса комбинирования моделей. |
| Развертывание модели | 1) Несоответствие версий ПО при обучении и в production-среде. 2) Отсутствие необходимых входных данных в production. | 1) Синхронизация версий ПО и зависимостей между средами разработки и production. 2) Использование контейнеризации (Docker) с документированием спецификаций и версий образов. 3) Использование единого языка программирования для обучения и развертывания. |
Слабосвязанная архитектура (Модульность)
В своей книге "Accelerate" Gene Kim с соавторами утверждают: "Высокая производительность при разработке программного обеспечения достижима в системах любого типа при условии, что сами системы и команды, которые их создают и поддерживают, слабо связаны между собой. Это ключевое архитектурное свойство позволяет командам легко тестировать и развертывать отдельные компоненты или сервисы даже при росте организации и увеличении количества используемых систем. Таким образом, организации могут повышать свою продуктивность в процессе масштабирования."
Авторы также подчеркивают важность "использования слабосвязанной архитектуры, поскольку она определяет способность команды тестировать и развертывать приложения по требованию без необходимости координации с другими сервисами. Слабосвязанная архитектура позволяет командам работать независимо, не полагаясь на поддержку и сервисы других команд, что в свою очередь ускоряет работу и повышает ценность для организации."
Однако в контексте ML-систем достижение слабой связанности (loose coupling) между компонентами может быть более сложным, чем в традиционном программном обеспечении. ML-системы часто имеют размытые границы между компонентами. Например, выходные данные одной ML-модели могут служить входными данными для другой, создавая сложные взаимозависимости, которые влияют друг на друга как при обучении, так и при тестировании.
Для достижения базовой модульности рекомендуется начать со структурирования ML-проекта. Существуют специальные шаблоны, помогающие создать стандартизированную структуру проекта, такие как:
Метрики доставки ML-систем (4 ключевые метрики из "Accelerate")
В исследовании State of DevOps 2019 были выделены четыре ключевые метрики, характеризующие эффективность разработки и развертывания программного обеспечения в высокопроизводительных организациях: Частота развертывания (Deployment Frequency), Время выполнения изменений (Lead Time for Changes), Среднее время восстановления (Mean Time To Restore) и Доля неуспешных изменений (Change Fail Percentage). Эти метрики оказались особенно полезными для оценки и совершенствования процесса доставки ML-систем. Рассмотрим каждую метрику подробнее и их применение в контексте MLOps.
| Метрика | DevOps | MLOps |
|---|---|---|
| Частота развертывания (Deployment Frequency) | Как часто организация выпускает код в production или делает его доступным конечным пользователям? | В контексте ML частота развертывания зависит от двух факторов: 1) Требований к обновлению модели, которые определяются: 1.1) Метриками деградации модели 1.2) Доступностью новых данных 2) Степени автоматизации процесса развертывания - от полностью ручного до автоматизированного CI/CD pipeline |
| Время выполнения изменений (Lead Time for Changes) | Время от внесения изменений в код до успешного запуска в production | Для ML-систем это время складывается из: 1) Длительности исследовательской фазы до готовности модели к развертыванию 2) Времени обучения модели 3) Продолжительности процесса развертывания, включая все ручные этапы |
| Среднее время восстановления (MTTR) | Время, необходимое для восстановления сервиса после инцидента или сбоя, влияющего на пользователей | В ML-системах MTTR зависит от: 1) Времени на диагностику и исправление проблем 2) Длительности переобучения модели, если это необходимо 3) Времени отката к предыдущей стабильной версии модели |
| Доля неуспешных изменений (Change Failure Rate) | Процент изменений, приводящих к ухудшению работы сервиса и требующих исправления | В ML измеряется как: 1) Разница в ключевых метриках качества (Precision, Recall, F1-score и др.) между текущей и предыдущей версиями модели 2) Результаты A/B-тестирования новых версий моделей |
Для повышения эффективности процесса разработки и внедрения ML-систем критически важно отслеживать эти четыре метрики. Практический путь к улучшению показателей - внедрение автоматизированных CI/CD-пайплайнов и применение подхода test-driven development ко всем компонентам системы: данным, ML-моделям и программному коду.
Краткий обзор принципов и лучших практик MLOps
Полный цикл разработки ML-систем включает три ключевых компонента, в которых могут происходить изменения: Данные, ML-модель и Код. Это означает, что в системах, основанных на машинном обучении, триггером для сборки может служить изменение в любом из этих компонентов или их комбинация. В таблице ниже представлены основные принципы MLOps для создания программного обеспечения на основе машинного обучения:
| Принципы MLOps | Данные | ML-модель | Код |
|---|---|---|---|
| Версионирование | 1) Пайплайны подготовки данных<br>2) Хранилище признаков (Feature store)<br>3) Наборы данных<br>4) Метаданные | 1) Пайплайн обучения модели<br>2) Модель (как объект)<br>3) Гиперпараметры<br>4) Система отслеживания экспериментов | 1) Код приложения<br>2) Конфигурационные файлы |
| Тестирование | 1) Валидация данных (выявление аномалий)<br>2) Модульное тестирование процесса создания признаков | 1) Модульное тестирование спецификации модели<br>2) Интеграционное тестирование пайплайна обучения<br>3) Валидация модели перед внедрением<br>4) Тестирование на устаревание (в production)<br>5) Проверка релевантности и корректности<br>6) Тестирование нефункциональных требований (безопасность, справедливость, интерпретируемость) | 1) Модульное тестирование<br>2) Сквозное интеграционное тестирование |
| Автоматизация | 1) Трансформация данных<br>2) Создание и обработка признаков | 1) Пайплайн обработки данных<br>2) Пайплайн обучения модели<br>3) Подбор гиперпараметров | 1) Развертывание модели через CI/CD<br>2) Сборка приложения |
| Воспроизводимость | 1) Резервное копирование данных<br>2) Версионирование данных<br>3) Сохранение метаданных<br>4) Версионирование процесса создания признаков | 1) Идентичность настроек гиперпараметров между dev и prod<br>2) Сохранение порядка признаков<br>3) Для ансамблей: идентичность комбинации моделей<br>4) Документирование псевдокода модели | 1) Идентичность версий зависимостей в dev и prod<br>2) Единый технический стек для всех сред<br>3) Воспроизведение результатов через контейнеры или виртуальные машины |
| Развертывание | 1) Единое хранилище признаков для dev и prod | 1) Контейнеризация ML-стека<br>2) REST API<br>3) Локальное, облачное или периферийное размещение | 1) Локальное, облачное или периферийное размещение |
| Мониторинг | 1) Отслеживание изменений в распределении данных<br>2) Сравнение признаков в обучении и эксплуатации | 1) Отслеживание деградации модели<br>2) Контроль численной стабильности<br>3) Мониторинг производительности | 1) Оценка качества предсказаний на рабочих данных |
Помимо следования принципам MLOps, внедрение следующих лучших практик поможет снизить технический долг ML-проекта:
| Лучшие практики MLOps | Данные | ML-модель | Код |
|---|---|---|---|
| Документация | 1) Описание источников данных<br>2) Обоснование выбора источников данных<br>3) Методология разметки | 1) Критерии выбора модели<br>2) Дизайн экспериментов<br>3) Документирование логики модели | 1) Процедура развертывания<br>2) Инструкция по локальному запуску |
| Структура проекта | 1) Каталог для исходных и обработанных данных<br>2) Каталог для пайплайна обработки данных<br>3) Каталог тестов для методов обработки | 1) Каталог для обученных моделей<br>2) Каталог для ноутбуков<br>3) Каталог для инженерии признаков<br>4) Каталог для разработки моделей | 1) Каталог для скриптов<br>2) Каталог для тестов<br>3) Каталог для файлов развертывания |