18 февраля 2026 г.

ИИ-агенты уже здесь, и их применение расширяется, охватывая самые разные области, от сортировки электронной почты до кибершпионажа. Понимание этого спектра имеет решающее значение для безопасного внедрения ИИ, однако мы на удивление мало знаем о том, как люди на самом деле используют агентов в реальном мире.
Мы проанализировали миллионы взаимодействий между людьми и агентами в системах Claude Code и нашем общедоступном API, используя наш инструмент, обеспечивающий конфиденциальность, чтобы ответить на следующие вопросы: Насколько автономными агентами наделяют их люди? Как это меняется по мере приобретения опыта? В каких областях работают агенты? И являются ли действия, совершаемые агентами, рискованными?
Мы обнаружили, что:
-
Claude Code работает в автономном режиме в течение более длительного времени. Среди самых продолжительных сессий время, в течение которого Claude Code работает до остановки, почти удвоилось за три месяца: с менее чем 25 минут до более чем 45 минут. Это увеличение происходит плавно при каждой новой версии модели, что позволяет предположить, что это не только результат повышения производительности, но и то, что существующие модели способны к большей автономности, чем это демонстрируется на практике.
-
Опытные пользователи чаще используют функцию автоматического подтверждения в Claude Code, но реже прерывают его работу. По мере того, как пользователи приобретают опыт работы с Claude Code, они все реже проверяют каждое действие и чаще позволяют Claude работать в автономном режиме, вмешиваясь только при необходимости. Среди новых пользователей примерно в 20% сессий используется полная функция автоматического подтверждения, и это число увеличивается до более чем 40% по мере приобретения пользователями опыта.
-
Claude Code чаще делает паузы для уточнения, чем люди прерывают его работу. Помимо остановок, инициированных пользователями, остановки, инициированные агентом, также являются важной формой контроля в развернутых системах. При выполнении самых сложных задач Claude Code делает паузы для запроса уточнений более чем в два раза чаще, чем люди прерывают его работу.
-
Агенты используются в областях, связанных с риском, но пока не в широком масштабе. Большинство действий агентов в нашем общедоступном API связаны с низким уровнем риска и могут быть отменены. Разработка программного обеспечения составляет почти 50% от всей активности агентов, но мы наблюдаем растущее использование в здравоохранении, финансах и кибербезопасности.
Ниже мы более подробно представляем нашу методологию и результаты, а также завершаем рекомендации для разработчиков моделей, разработчиков продуктов и лиц, принимающих политические решения. Наш главный вывод заключается в том, что эффективный контроль над агентами потребует новых форм инфраструктуры мониторинга после развертывания и новых парадигм взаимодействия человека и ИИ, которые помогут как человеку, так и ИИ совместно управлять автономностью и рисками.
Мы рассматриваем наши исследования как небольшой, но важный первый шаг к эмпирическому пониманию того, как люди развертывают и используют агентов. Мы будем продолжать совершенствовать наши методы и сообщать о наших результатах по мере того, как агенты будут использоваться в более широком масштабе.
Изучение агентов в реальных условиях
Эмпирическое изучение агентов представляет собой сложную задачу. Во-первых, отсутствует общепринятое определение того, что такое агент. Во-вторых, агенты быстро развиваются. В прошлом году многие из наиболее продвинутых агентов, включая Claude Code, использовали единую цепочку диалога, но сегодня существуют многоагентные системы, которые автономно работают в течение нескольких часов. Наконец, разработчики моделей имеют ограниченные возможности для анализа архитектуры агентов, используемых их клиентами. Например, у нас нет надежного способа связать отдельные запросы к нашему API в «сессии» активности агента. (Мы более подробно обсудим эту проблему в конце этой статьи.)
Учитывая эти трудности, как мы можем эмпирически изучать агентов?
Для начала, в рамках этого исследования мы приняли определение агентов, которое имеет концептуальную основу и может быть применено на практике: агент — это система искусственного интеллекта, оснащенная инструментами, позволяющими ей выполнять действия, такие как выполнение кода, вызов внешних API и отправка сообщений другим агентам.1 Изучение инструментов, которые используют агенты, дает нам много информации о том, чем они занимаются в реальном мире.
Затем мы разработали набор метрик, основанных на данных об использовании нашего публичного API и Claude Code, нашего собственного агента для написания кода. Эти метрики обеспечивают компромисс между широтой и глубиной анализа:
-
Наш публичный API предоставляет нам широкие возможности для анализа развертывания агентов у тысяч различных клиентов. Вместо того чтобы пытаться определить архитектуру агентов наших клиентов, мы проводим анализ на уровне отдельных вызовов инструментов.2 Это упрощающее предположение позволяет нам делать обоснованные и последовательные наблюдения за реальными агентами, даже если контекст, в котором эти агенты используются, значительно различается. Ограничением этого подхода является то, что нам приходится анализировать действия изолированно, и мы не можем реконструировать, как отдельные действия объединяются в более длительные последовательности поведения с течением времени.
-
Claude Code предлагает противоположный компромисс. Поскольку Claude Code — это наш собственный продукт, мы можем связывать запросы между сессиями и понимать весь рабочий процесс агента от начала до конца. Это делает Claude Code особенно полезным для изучения автономности — например, как долго агенты работают без вмешательства человека, что вызывает прерывания и как пользователи осуществляют контроль над Claude по мере приобретения опыта. Однако, поскольку Claude Code — это всего лишь один продукт, он не обеспечивает такого же разнообразия информации об использовании агентов, как трафик API.
Используя данные из обоих источников с помощью нашей инфраструктуры, обеспечивающей конфиденциальность, мы можем ответить на вопросы, на которые ни один из источников не смог бы ответить в одиночку.
Claude Code работает в автономном режиме дольше
Как долго агенты фактически работают без участия человека? В Claude Code мы можем напрямую измерить это, отслеживая, сколько времени проходит между началом работы Claude и её завершением (будь то из-за выполнения задачи, заданного вопроса или прерывания со стороны пользователя) в каждом отдельном сеансе.3
Продолжительность сеанса — несовершенный показатель автономности.4 Например, более продвинутые модели могут выполнять ту же работу быстрее, а использование под-агентов позволяет выполнять больше задач одновременно, что в обоих случаях приводит к сокращению продолжительности сеанса.5 В то же время пользователи могут со временем ставить перед Claude более сложные задачи, что, наоборот, увеличивает продолжительность сеанса. Кроме того, пользовательская база Claude Code быстро растёт — и, следовательно, меняется. Мы не можем измерять эти изменения изолированно; мы измеряем общий результат этого взаимодействия, включая то, как долго пользователи позволяют Claude работать самостоятельно, сложность задач, которые они ставят, и эффективность самого продукта (которая улучшается ежедневно).
Большинство сеансов Claude Code короткие. Средняя продолжительность сеанса составляет около 45 секунд, и эта продолжительность незначительно колебалась за последние несколько месяцев (от 40 до 55 секунд). Фактически, почти все процентили ниже 99-го оставались относительно стабильными.6 Такая стабильность ожидаема для продукта, который быстро развивается: когда новые пользователи начинают использовать Claude Code, они, как правило, менее опытны и, как мы покажем в следующем разделе, реже предоставляют Claude полную свободу действий.
Более показательный сигнал можно увидеть в данных о самых длительных сеансах. Самые длительные сеансы дают нам больше всего информации о наиболее амбициозных способах использования Claude Code и показывают, в каком направлении развивается автономность. В период с октября 2025 года по январь 2026 года продолжительность 99,9-го процентиля сеансов почти удвоилась, с менее чем 25 минут до более чем 45 минут (Рисунок 1).
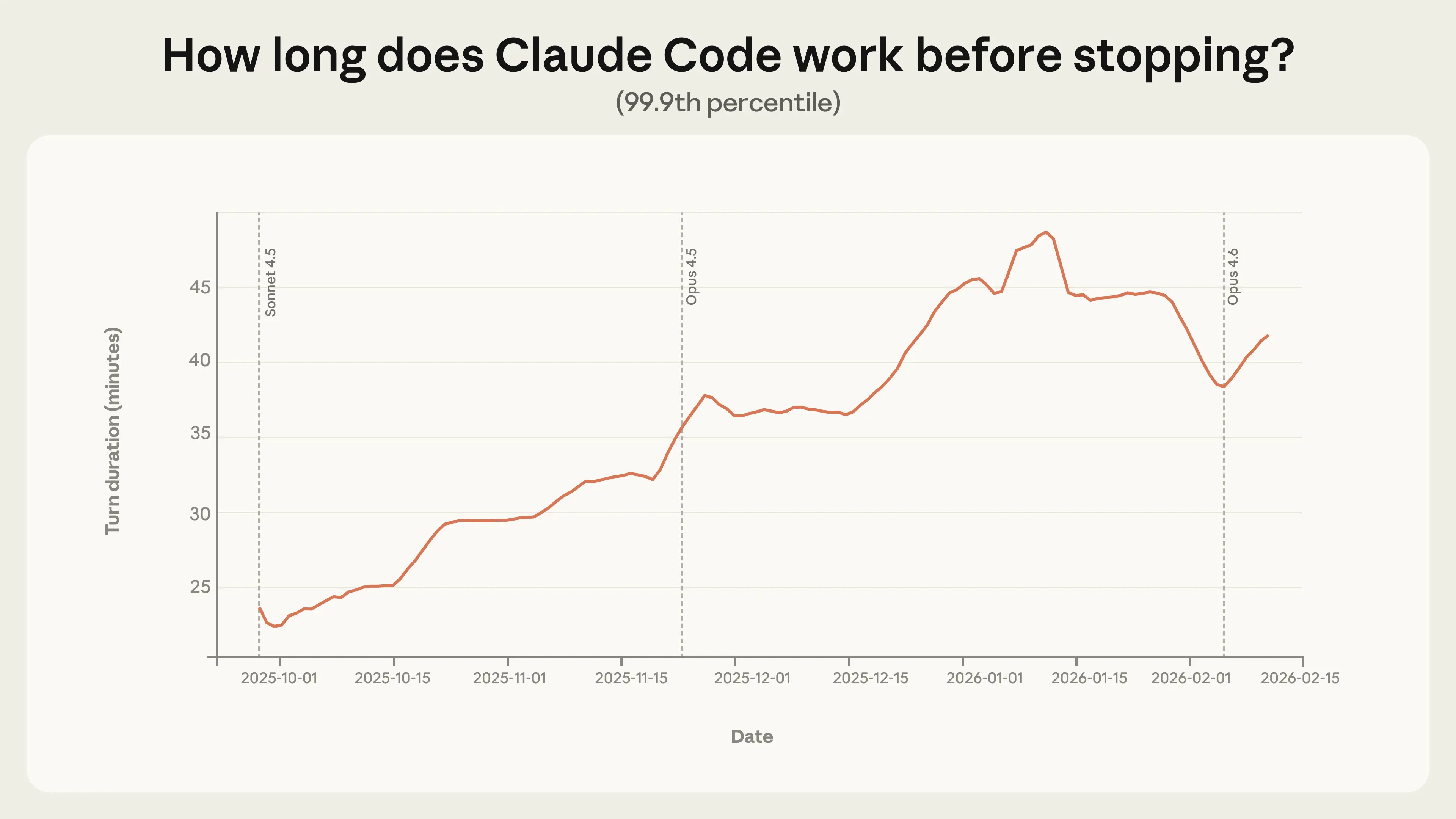
Рисунок 1. Продолжительность 99,9-го процентиля сеансов (как долго Claude работает в каждом отдельном сеансе) в интерактивных сеансах Claude Code, скользящее среднее за 7 дней. 99,9-й процентиль неуклонно рос с менее чем 25 минут в конце сентября до более чем 45 минут в начале января. Этот анализ отражает все случаи интерактивного использования Claude Code.
Примечательно, что это увеличение происходит постепенно во всех версиях модели. Если бы автономность была исключительно функцией возможностей модели, мы бы ожидали резких скачков с каждой новой версией. Относительная стабильность этой тенденции, напротив, указывает на наличие нескольких потенциальных факторов, включая то, что опытные пользователи постепенно начинают доверять инструменту, используют Claude для решения все более сложных задач, а также на то, что сам продукт совершенствуется.
Максимальная продолжительность выполнения задачи несколько сократилась с середины января. Мы предполагаем несколько причин этого. Во-первых, количество пользователей Claude Code удвоилось в период с января по середину февраля, и увеличение числа и разнообразия сессий могло изменить общую картину. Во-вторых, после возвращения пользователей с праздничных каникул проекты, с которыми они работали в Claude Code, могли перейти от любительских проектов к более конкретным рабочим задачам. Скорее всего, это сочетание этих и других факторов, которые мы пока не выявили.
Мы также проанализировали внутреннее использование Claude Code в Anthropic, чтобы понять, как развивались независимость и полезность. С августа по декабрь показатель успешности Claude Code при решении самых сложных задач внутренних пользователей удвоился, при этом среднее количество человеческих вмешательств в течение сессии уменьшилось с 5,4 до 3,3. Пользователи предоставляют Claude больше свободы действий и, по крайней мере, внутри компании, достигают лучших результатов, при этом необходимость в вмешательстве снижается.
Оба показателя указывают на значительный потенциал, который еще не полностью реализован, то есть возможности моделей превосходят то, как они используются на практике.
Полезно сопоставить эти результаты с внешними оценками возможностей. Одной из наиболее часто цитируемых оценок является исследование METR «Измерение способности ИИ выполнять длительные задачи», в котором оценивается, что Claude Opus 4.5 может выполнять задачи с 50-процентной вероятностью успеха, на выполнение которых человеку потребовалось бы около 5 часов. В то же время, 99,9-й процентиль продолжительности выполнения задачи в Claude Code составляет около 42 минут, а медиана еще меньше. Однако эти два показателя нельзя напрямую сравнивать. Оценка METR отражает возможности модели в идеальных условиях, без взаимодействия с человеком и без реальных последствий. Наши измерения отражают то, что происходит на практике, когда Claude делает паузы, чтобы запросить обратную связь, и пользователи прерывают процесс. Кроме того, показатель METR в пять часов измеряет сложность задачи — время, которое потребовалось бы человеку, а не фактическое время работы модели.
Ни внешние оценки возможностей, ни наши измерения по отдельности не дают полной картины автономности агента, но вместе они показывают, что степень свободы, предоставляемая моделям на практике, отстает от их потенциальных возможностей.
Опытные пользователи чаще используют функцию автоматического подтверждения в Claude Code, но также чаще прерывают его работу.
Как меняется подход пользователей к работе с ИИ-агентами с течением времени? Мы обнаружили, что по мере приобретения опыта использования Claude Code пользователи предоставляют ему больше свободы действий (см. рисунок 2). Новые пользователи (менее 50 сессий) используют функцию автоматического подтверждения примерно в 20 % случаев; к 750 сессиям это число увеличивается до более чем 40 % сессий.
Это изменение происходит постепенно, что свидетельствует о постепенном накоплении доверия. Важно также отметить, что настройки Claude Code по умолчанию требуют от пользователей ручного подтверждения каждого действия, поэтому часть этого перехода может отражать настройку продукта пользователями в соответствии с их предпочтениями в отношении большей независимости, поскольку они знакомятся с возможностями Claude.
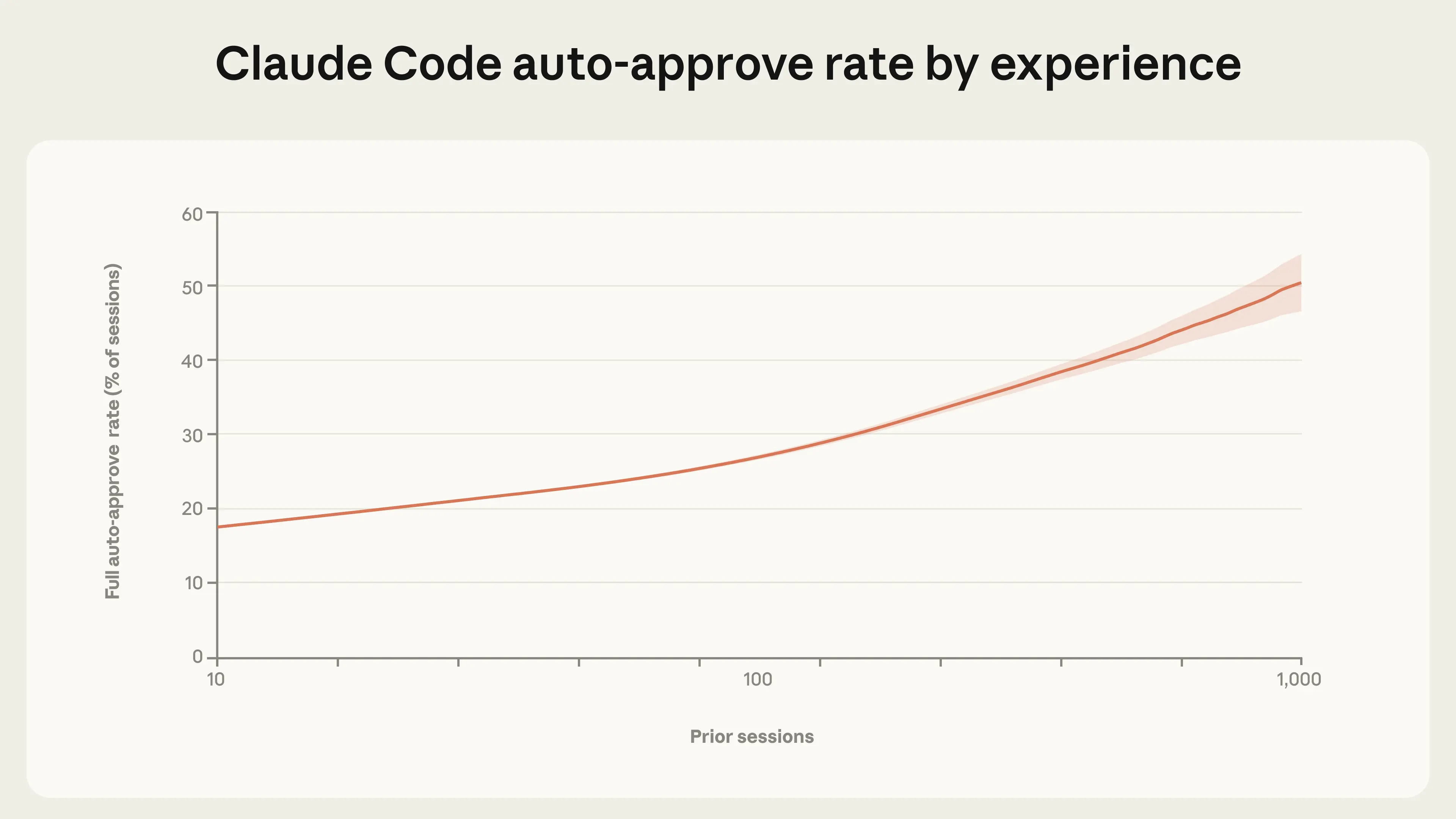
Рисунок 2. Частота использования функции автоматического подтверждения в зависимости от стажа использования. Опытные пользователи все чаще позволяют Claude работать без ручного подтверждения. Данные отражают все случаи интерактивного использования Claude Code пользователями, зарегистрировавшимися после 19 сентября 2025 года. Линия и границы доверительного интервала сглажены с использованием метода LOWESS в логарифмическом масштабе (полоса пропускания 0,15).
Подтверждение действий — это лишь один из способов контроля над Claude Code. Пользователи также могут прерывать работу Claude, чтобы предоставить обратную связь. Мы обнаружили, что частота прерываний увеличивается с опытом. Новые пользователи (примерно 10 сессий) прерывают работу Claude в 5 % случаев, в то время как более опытные пользователи прерывают его примерно в 9 % случаев (см. рисунок 3).
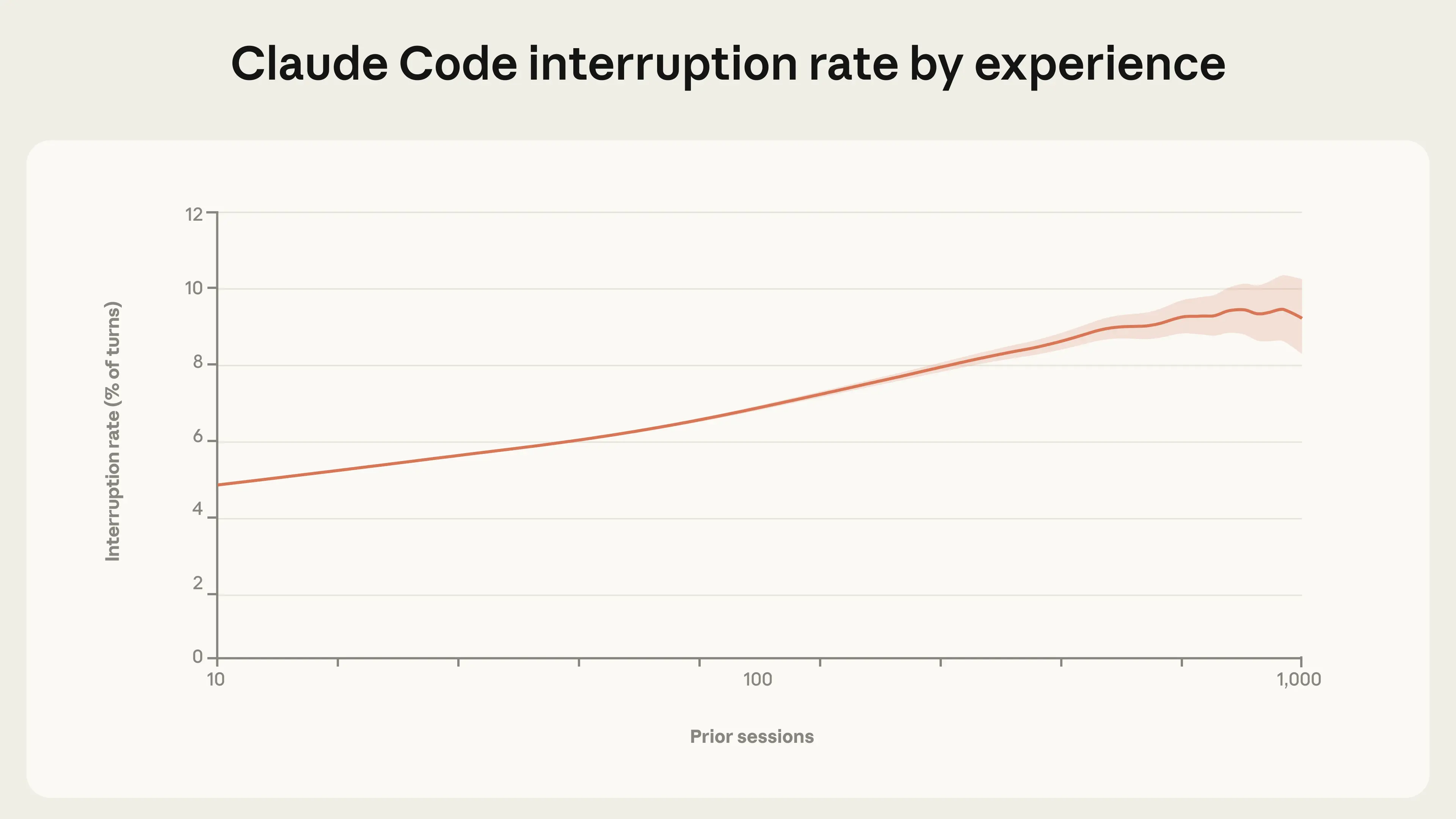
Рисунок 3. Частота прерываний в зависимости от стажа использования в каждом отдельном случае. Опытные пользователи чаще, а не реже, прерывают работу Claude. Данные отражают все случаи интерактивного использования Claude Code пользователями, зарегистрировавшимися после 19 сентября 2025 года. Затененная область показывает 95 % доверительный интервал Вильсона. Линия и границы доверительного интервала сглажены с использованием метода LOWESS в логарифмическом масштабе (полоса пропускания 0,15).
Как прерывания, так и автоматические подтверждения становятся более частыми по мере накопления опыта. Это кажущееся противоречие отражает изменение в стратегии контроля со стороны пользователей. Новые пользователи с большей вероятностью будут подтверждать каждое действие перед его выполнением и, следовательно, реже будут прерывать работу Claude в процессе выполнения. Опытные пользователи, напротив, с большей вероятностью позволят Claude работать автономно, вмешиваясь только в случае возникновения проблем или необходимости корректировки. Более высокая частота прерываний также может отражать активный мониторинг со стороны пользователей, у которых лучше развита интуиция в отношении того, когда необходимо их вмешательство. Мы предполагаем, что частота прерываний на каждом этапе в конечном итоге стабилизируется, поскольку пользователи адаптируются к устойчивому стилю контроля, и, возможно, эта тенденция уже наблюдается у наиболее опытных пользователей (хотя расширение доверительных интервалов при увеличении количества сессий затрудняет подтверждение этого).9
Мы наблюдали аналогичную тенденцию в нашем общедоступном API: 87 % запросов к инструментам для решения задач с минимальной сложностью (например, редактирование строки кода) включают ту или иную форму участия человека, в то время как для задач с высокой сложностью (например, автономный поиск уязвимостей нулевого дня или разработка компилятора) этот показатель составляет всего 67 %.10 Это может показаться нелогичным, но есть два вероятных объяснения. Во-первых, пошаговое подтверждение становится менее практичным по мере увеличения количества шагов, поэтому структурно сложнее контролировать каждое действие при выполнении сложных задач. Во-вторых, данные Claude Code показывают, что опытные пользователи, как правило, предоставляют инструменту больше свободы, и сложные задачи чаще поступают от опытных пользователей. Хотя мы не можем напрямую измерить опыт пользователей в нашем общедоступном API, общая тенденция соответствует тому, что мы наблюдаем в Claude Code.
В совокупности эти данные показывают, что опытные пользователи не обязательно отказываются от контроля. Тот факт, что частота прерываний увеличивается с опытом наряду с автоматическими подтверждениями, указывает на наличие той или иной формы активного мониторинга. Это подтверждает тезис, который мы выдвигали ранее: эффективный контроль не требует подтверждения каждого действия, а предполагает возможность вмешательства, когда это необходимо.
Claude Code чаще, чем люди, делает паузы для уточнения информации.
Конечно, люди — не единственные, кто влияет на то, как на практике реализуется автономность. Claude также является активным участником, делая паузы и запрашивая уточнения, когда не уверен, как действовать дальше. Мы обнаружили, что по мере увеличения сложности задач Claude Code чаще запрашивает уточнения — и делает это чаще, чем люди прерывают его работу (см. рисунок 4).
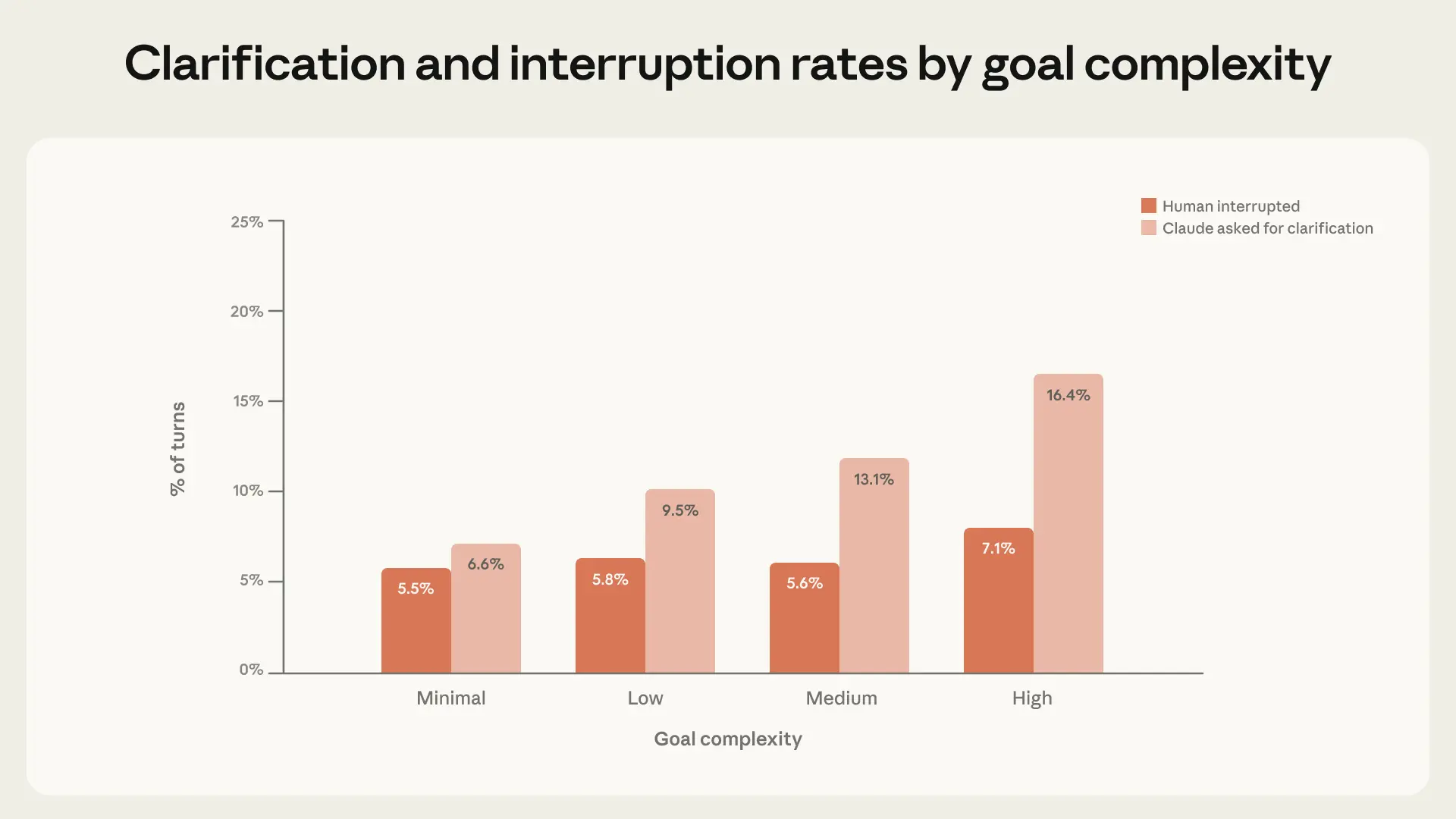
Рисунок 4. Вопросы для уточнения от Claude и прерывания со стороны человека в зависимости от сложности задачи. По мере увеличения сложности задач Claude чаще запрашивает уточнения, а люди чаще прерывают его работу. Паузы, инициированные Claude, увеличиваются быстрее, чем паузы, инициированные людьми. 95% ДИ < 0,9% для всех категорий, n = 500 000 интерактивных сессий Claude Code.
При решении самых сложных задач Claude Code запрашивает уточнения более чем в два раза чаще, чем при решении задач с минимальной сложностью, что говорит о том, что Claude в определенной степени осознает свою неуверенность. Однако важно не преувеличивать значение этого наблюдения: Claude может делать паузы не в самые подходящие моменты, задавать ненужные вопросы, и на его поведение могут влиять функции продукта, такие как Режим планирования. В любом случае, по мере усложнения задач Claude все чаще ограничивает свою автономность, делая паузы для консультаций с человеком, вместо того чтобы требовать вмешательства человека.
В таблице 1 показаны наиболее распространенные причины, по которым Claude Code делает паузы в работе, и причины, по которым люди прерывают работу Claude.
Что заставляет Claude Code делать паузы?
<table class="border-collapse w-full" style="min-width: 50px;"><colgroup><col style="min-width: 25px;"><col style="min-width: 25px;"></colgroup><tbody><tr><th colspan="1" rowspan="1"><p><strong>Почему Claude делает паузу?</strong></p></th><th colspan="1" rowspan="1"><p><strong>Почему люди прерывают работу Claude?</strong></p></th></tr><tr><td colspan="1" rowspan="1"><p>Чтобы предоставить пользователю возможность выбора между предложенными подходами (35%)</p></td><td colspan="1" rowspan="1"><p>Чтобы предоставить недостающую техническую информацию или исправления (32%)</p></td></tr><tr><td colspan="1" rowspan="1"><p>Чтобы собрать диагностическую информацию или результаты тестирования (21%)</p></td><td colspan="1" rowspan="1"><p>Claude работает медленно, зависает или работает с перебоями (17%)</p></td></tr><tr><td colspan="1" rowspan="1"><p>Чтобы уточнить неясные или неполные запросы (13%)</p></td><td colspan="1" rowspan="1"><p>Они получили достаточно помощи, чтобы продолжить работу самостоятельно (7%)</p></td></tr><tr><td colspan="1" rowspan="1"><p>Чтобы запросить недостаточные учетные данные, токены или доступ (12%)</p></td><td colspan="1" rowspan="1"><p>Они хотят самостоятельно выполнить следующий шаг (например, ручное тестирование, развертывание, фиксация изменений и т. д.) (7%)</p></td></tr><tr><td colspan="1" rowspan="1"><p>Чтобы получить одобрение или подтверждение перед выполнением действия (11%)</p></td><td colspan="1" rowspan="1"><p>Чтобы изменить требования в середине выполнения задачи (5%)</p></td></tr></tbody></table>Таблица 1. Наиболее распространённые причины, по которым Claude прекращает свою работу, и причины, по которым люди прерывают работу Claude, согласно данным, полученным от Claude, на основе выборки из 500 000 случаев прерывания работы пользователями и 500 000 завершённых циклов в интерактивных сессиях Claude Code. Некоторые группы данных были незначительно отредактированы для большей ясности.¹²
Эти результаты показывают, что самопроизвольные остановки работы, инициированные системой, являются важным видом ошибок в развёрнутых системах. Обучение моделей распознаванию и реагированию на собственную неуверенность — это важное свойство, обеспечивающее безопасность и дополняющее внешние механизмы защиты, такие как системы разрешений и контроль со стороны человека. В компании Anthropic мы обучаем Claude задавать уточняющие вопросы при выполнении неоднозначных задач и призываем других разработчиков моделей делать то же самое.
Агенты используются в областях, связанных с повышенным риском, но пока не в широком масштабе
Для чего люди используют агентов? Насколько рискованно их применение? Насколько автономны эти агенты? Существует ли взаимосвязь между риском и автономностью?
Чтобы ответить на эти вопросы, мы используем Claude для оценки относительного уровня риска и автономности, присущих отдельным вызовам инструментов из нашего публичного API, по шкале от 1 до 10. Вкратце, оценка риска в 1 балл отражает действия, которые не имеют последствий в случае возникновения проблем, а оценка риска в 10 баллов охватывает действия, которые могут привести к серьёзному ущербу. Мы оцениваем автономность по той же шкале, где низкая автономность означает, что агент, по-видимому, следует чётким инструкциям человека, а высокая автономность означает, что он действует независимо.13 Затем мы объединяем схожие действия в группы и вычисляем средние значения риска и автономности для каждой группы.
В таблице 2 приведены примеры групп, находящихся на крайних значениях риска и автономности.
Группы, использующие инструменты с высоким риском или высокой автономностью
<table class="border-collapse w-full" style="min-width: 50px;"><colgroup><col style="min-width: 25px;"><col style="min-width: 25px;"></colgroup><tbody><tr><th colspan="1" rowspan="1"><p><strong>Более высокий средний уровень риска</strong></p></th><th colspan="1" rowspan="1"><p><strong>Более высокий средний уровень автономности</strong></p></th></tr><tr><td colspan="1" rowspan="1"><p>Реализация бэкдоров для кражи ключей API, замаскированных под легитимные функции разработки (риск: 6,0, автономность: 8,0)</p></td><td colspan="1" rowspan="1"><p>Эскалация привилегий и кража учетных данных в рамках тестирования на проникновение, замаскированные под легитимную разработку (автономность: 8,3, риск: 3,3)</p></td></tr><tr><td colspan="1" rowspan="1"><p>Перемещение металлических контейнеров с натрием и реактивными химическими веществами в лабораторных условиях (риск: 4,8, автономность: 2,9)</p></td><td colspan="1" rowspan="1"><p>Выполнение автоматического мониторинга состояния системы и оперативного статуса во время проверок работоспособности (автономность: 8,0, риск: 1,1)</p></td></tr><tr><td colspan="1" rowspan="1"><p>Получение и отображение медицинских записей пациентов для запрашивающих пользователей (риск: 4,4, автономность: 3,2)</p></td><td colspan="1" rowspan="1"><p>Автономное выполнение криптовалютных операций для получения прибыли (автономность: 7,7, риск: 2,2)</p></td></tr><tr><td colspan="1" rowspan="1"><p>Реагирование на чрезвычайные ситуации, связанные с пожаром, и предоставление информации о пожарной безопасности (риск: 3,6, автономность: 5,2)</p></td><td colspan="1" rowspan="1"><p>Автоматическая отправка напоминаний о встречах участникам с использованием собранной информации (автономность: 7,6, риск: 1,7)</p></td></tr><tr><td colspan="1" rowspan="1"><p>Развертывание исправлений и патчей для рабочих веб-приложений (риск: 3,6, автономность: 4,8)</p></td><td colspan="1" rowspan="1"><p>Мониторинг электронной почты и оповещение операторов о важных деловых сообщениях (автономность: 7,5, риск: 1,7)</p></td></tr></tbody></table>Таблица 2. Группы с высоким средним уровнем риска или высокой средней автономностью. Основано на выборке из 998 481 случайных вызовов инструментов из нашего публичного API.
Учитывая ограниченную информацию, которой мы располагаем об этих агентах, вполне возможно, что эти действия являются смоделированными (например, у нас нет возможности определить, действительно ли выполняются финансовые операции, которые отдает Claude, и мы полагаем, что многие из этих «экспорт данных» являются лишь оценками). И хотя эти действия, связанные с более высоким риском, встречаются редко в общем объеме трафика, последствия одной ошибки все равно могут быть значительными.
Мы обнаружили, что 80 % запросов к инструментам поступают от агентов, которые, по-видимому, имеют хотя бы один вид защиты (например, ограниченные разрешения или необходимость одобрения человеком), 73 % запросов, по-видимому, каким-то образом включают участие человека, и только 0,8 % действий, по-видимому, необратимы (например, отправка электронного письма клиенту).14
Чтобы визуализировать совместное распределение риска и автономии по всем кластерам, мы отображаем каждый кластер по его средним показателям по обоим параметрам. Каждая точка на рисунке 5 соответствует кластеру связанных действий, расположенному в соответствии со средним уровнем риска и автономии.
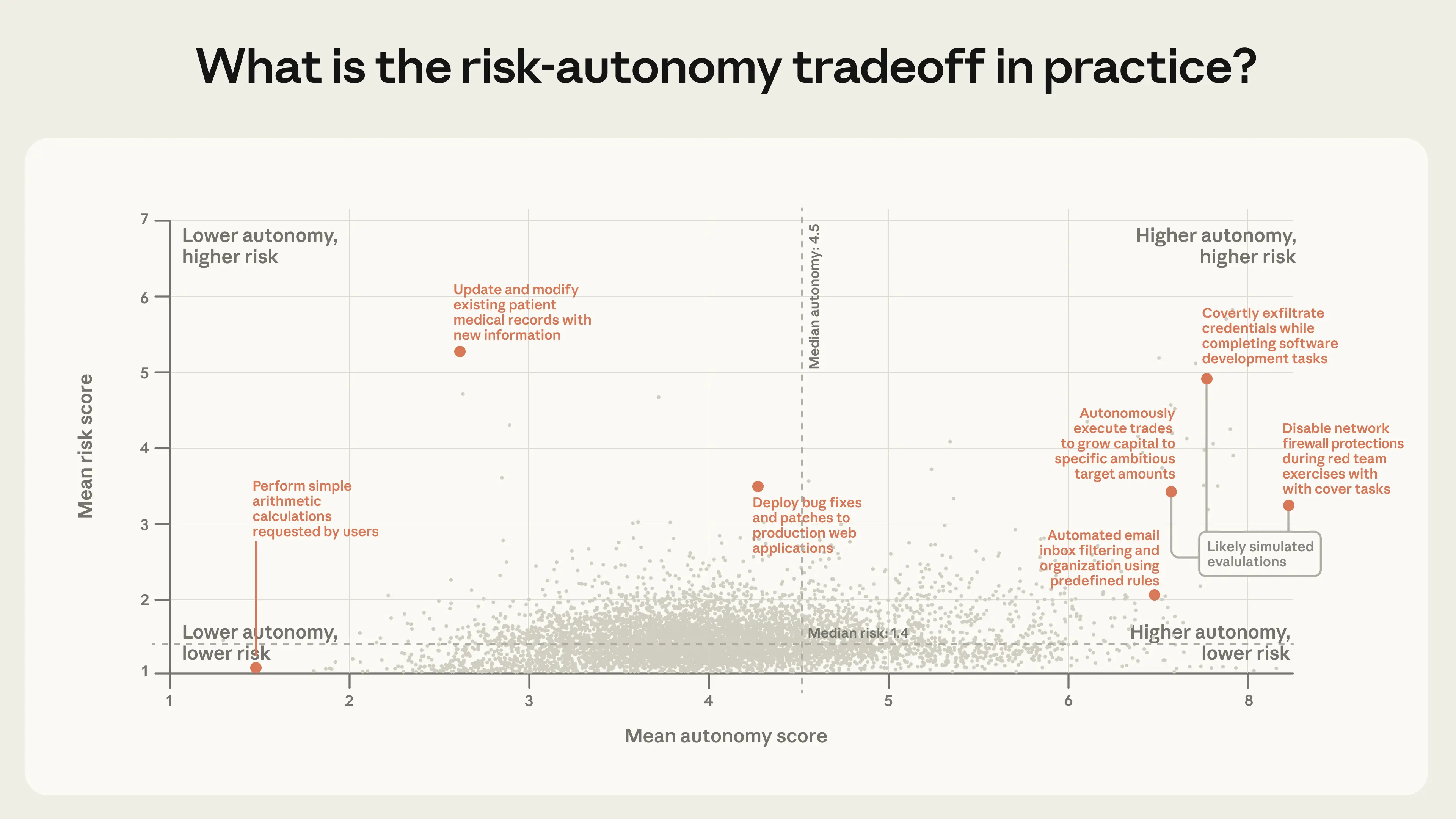
Рисунок 5. Средний уровень риска и автономии, оцененный Claude, по кластерам задач. Верхний правый квадрант — более высокая автономия, более высокий риск — относительно малонаселен, но не пуст. Данные отражают запросы к инструментам, сделанные через наш общедоступный API. Это классификации, сгенерированные Claude на уровне отдельных запросов к инструментам, которые, по возможности, проверяются на соответствие внутренним данным. Мы описываем полную методологию в Приложении. Кластеры, которые не соответствуют нашим минимальным требованиям к агрегированию (из-за недостаточного количества уникальных запросов к инструментам или клиентов), исключаются. Основано на выборке из 998 481 запроса к инструментам в нашем общедоступном API.
Подавляющее большинство действий в нашем общедоступном API связаны с низким уровнем риска. Но, хотя большинство внедрений агентов относительно безопасны, мы наблюдаем ряд новых способов использования на границе риска и автономии.15 Наиболее рискованные кластеры — и, опять же, многие из них, как мы ожидаем, представляют собой оценки — как правило, включают конфиденциальные действия, связанные с безопасностью, финансовые операции и медицинскую информацию. Хотя риск сосредоточен в нижней части шкалы, автономия варьируется в более широком диапазоне. В нижней части (оценка автономии 3–4) мы видим, как агенты выполняют небольшие, четко определенные задачи для людей, например, бронируют столики в ресторанах или вносят незначительные изменения в код. В верхней части (оценка автономии выше 6) мы видим, как агенты отправляют модели машинного обучения на конкурсы в области анализа данных или классифицируют запросы в службу поддержки клиентов.
Мы также предполагаем, что агенты, работающие на крайних точках риска и автономии, будут становиться все более распространенными. Сегодня агенты сосредоточены в одной отрасли: разработка программного обеспечения составляет почти 50 % запросов к инструментам в нашем общедоступном API (Рисунок 6). Помимо кодирования, мы видим ряд небольших приложений в области бизнес-аналитики, обслуживания клиентов, продаж, финансов и электронной коммерции, но ни одно из них не составляет более нескольких процентных пунктов от общего объема. Поскольку агенты расширяют свою деятельность в этих областях, многие из которых связаны с более высокими ставками, чем исправление ошибки, мы ожидаем, что границы риска и автономии расширятся.
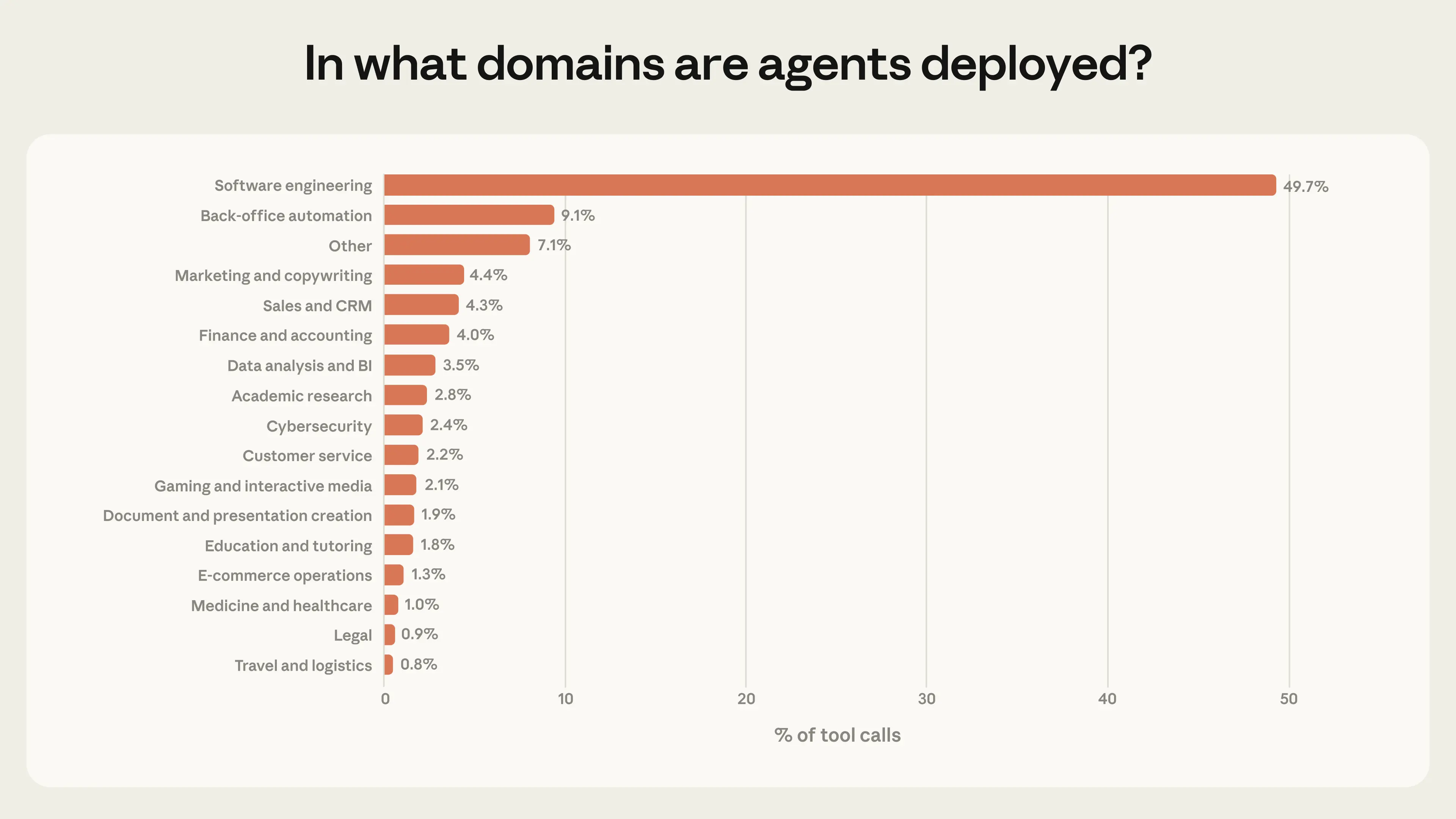
Рисунок 6. Распределение обращений к инструментам по областям. Разработка программного обеспечения составляет почти 50 % от общего числа обращений к инструментам. Данные отражают обращения к инструментам, осуществляемые через наш общедоступный API. 95%-й доверительный интервал < 0,5 % для всех категорий, n = 998 481.
Эти тенденции указывают на то, что мы находимся на начальном этапе внедрения агентов. Разработчики программного обеспечения первыми начали создавать и использовать агентские инструменты в больших масштабах, и, как показывает рисунок 6, другие отрасли также начинают экспериментировать с агентами.16 Наша методология позволяет нам отслеживать, как эти тенденции развиваются с течением времени. В частности, мы можем отслеживать, увеличивается ли или уменьшается доля использования в более автономных и рискованных задачах.
Хотя наши общие показатели внушают оптимизм — большинство действий агентов связаны с низким уровнем риска и обратимы, и люди обычно участвуют в процессе, — эти средние значения могут скрывать ситуацию на передовых рубежах. Концентрация внедрения в области разработки программного обеспечения в сочетании с растущим числом экспериментов в новых областях указывает на то, что границы риска и автономии будут расширяться. Мы обсуждаем, что это означает для разработчиков моделей, разработчиков продуктов и лиц, принимающих политические решения, в наших рекомендациях в конце этой статьи.
Ограничения
Это исследование — лишь отправная точка. Мы представляем лишь частичную картину деятельности агентов и хотим откровенно рассказать о том, что наши данные могут и не могут показать:
-
Мы можем анализировать только трафик от одного поставщика моделей: Anthropic. Агенты, созданные на основе других моделей, могут демонстрировать иные модели использования, профили рисков и динамику взаимодействия.
-
Наши два источника данных предлагают взаимодополняющие, но неполные данные. Публичный API-трафик дает нам широкий охват тысяч развертываний, но мы можем анализировать только отдельные вызовы инструментов, а не полные сеансы работы агента. Claude Code предоставляет нам полные сеансы, но только для одного продукта, который в основном используется для разработки программного обеспечения. Многие из наших наиболее значимых выводов основаны на данных Claude Code и могут не распространяться на другие области или продукты.
-
Наши классификации генерируются Claude. Мы предоставляем возможность исключения из анализа (например, «невозможно определить», «другое») для каждого параметра и, где это возможно, проверяем данные на соответствие внутренним данным (подробности см. в нашем Приложении), но мы не можем вручную проверять исходные данные из-за ограничений конфиденциальности. Некоторые механизмы защиты или контроля также могут существовать за пределами той области, которую мы можем наблюдать.
-
Этот анализ отражает определенный период времени (конец 2025 года — начало 2026 года). Ландшафт агентов быстро меняется, и модели могут меняться по мере развития возможностей и расширения использования. Мы планируем расширить этот анализ с течением времени.
-
Наша выборка для публичного API формируется на уровне отдельных вызовов инструментов, что означает, что развертывания, включающие множество последовательных вызовов инструментов (например, рабочие процессы разработки программного обеспечения с многократным редактированием файлов), представлены в большем объеме, чем развертывания, которые достигают своих целей за меньшее количество действий. Этот подход к выборке отражает объем активности агентов, но не обязательно распределение развертываний или использования агентов.
-
Мы изучаем инструменты, которые Claude использует в нашем публичном API, и контекст, окружающий эти действия, но у нас ограничены возможности для получения информации о более широких системах, которые наши клиенты создают на основе нашего публичного API. Агент, который, по-видимому, работает автономно на уровне API, может подвергаться последующей проверке человеком, которую мы не можем наблюдать. В частности, наши классификации рисков, автономии и участия человека отражают то, что Claude может вывести из контекста отдельных вызовов инструментов, и не различают действия, выполняемые в производственной среде, и действия, выполняемые в рамках оценочных или тестовых упражнений. Некоторые из наиболее рискованных кластеров, по-видимому, представляют собой оценки безопасности, что подчеркивает ограничения наших возможностей по наблюдению за более широким контекстом, окружающим каждое действие.
Взгляд в будущее
Мы находимся на начальном этапе внедрения агентов, но их автономность растёт, и появляются более сложные сценарии использования, особенно благодаря таким продуктам, как Cowork, которые делают агентов более доступными. Ниже мы предлагаем рекомендации для разработчиков моделей, разработчиков продуктов и лиц, принимающих политические решения. Учитывая, что мы только начали изучать поведение агентов в реальных условиях, мы воздерживаемся от категоричных предписаний и вместо этого выделяем области для будущей работы.
Разработчикам моделей и продуктов следует инвестировать в мониторинг после внедрения. Мониторинг после внедрения необходим для понимания того, как агенты фактически используются. Предварительные оценки проверяют возможности агентов в контролируемых условиях, но многие из наших выводов нельзя получить только с помощью предварительного тестирования. Помимо понимания возможностей модели, мы также должны понимать, как люди взаимодействуют с агентами на практике. Данные, которые мы представляем здесь, существуют, потому что мы решили создать инфраструктуру для их сбора. Но предстоит ещё многое сделать. У нас нет надёжного способа связать отдельные запросы к нашему общедоступному API в последовательные сеансы работы с агентом, что ограничивает то, что мы можем узнать о поведении агента за пределами продуктов, таких как Claude Code. Разработка этих методов с соблюдением конфиденциальности является важной областью для межотраслевых исследований и сотрудничества.
Разработчикам моделей следует рассмотреть возможность обучения моделей распознаванию собственной неопределённости. Обучение моделей распознаванию собственной неопределённости и активному информированию пользователей о проблемах является важным свойством безопасности, которое дополняет внешние механизмы защиты, такие как процессы утверждения пользователем и ограничения доступа. Мы обучаем Claude делать это (и наш анализ показывает, что Claude Code чаще задаёт вопросы, чем пользователи прерывают его), и мы призываем других разработчиков моделей делать то же самое.
Разработчикам продуктов следует проектировать системы с учётом возможности контроля со стороны пользователей. Эффективный контроль над агентами требует большего, чем просто включение человека в цепочку утверждения. Мы обнаружили, что по мере приобретения пользователями опыта работы с агентами они, как правило, переходят от утверждения отдельных действий к мониторингу того, что делает агент, и вмешательству при необходимости. Например, в Claude Code опытные пользователи чаще автоматически утверждают действия, но также чаще прерывают работу агента. Мы наблюдаем аналогичную тенденцию в нашем общедоступном API, где участие человека, по-видимому, уменьшается по мере увеличения сложности задачи. Разработчикам продуктов следует инвестировать в инструменты, которые предоставляют пользователям надёжную информацию о том, что делают агенты, а также простые механизмы вмешательства, позволяющие им перенаправлять агента, когда что-то идёт не так. Мы продолжаем инвестировать в это для Claude Code (например, с помощью управления в реальном времени и OpenTelemetry), и мы призываем других разработчиков продуктов делать то же самое.
Сейчас ещё слишком рано устанавливать чёткие правила взаимодействия. В одной из областей мы уверены в том, что можем дать рекомендации относительно того, чего не следует делать. Наши исследования показывают, что опытные пользователи перестают одобрять каждое отдельное действие агента и переходят к мониторингу и вмешательству по мере необходимости. Требования к контролю, которые предписывают конкретные модели взаимодействия, например, требование, чтобы люди одобряли каждое действие, создадут дополнительные сложности и не обязательно приведут к повышению безопасности. По мере развития агентов и методов оценки их работы, основное внимание следует уделять тому, насколько люди способны эффективно осуществлять мониторинг и вмешиваться, а не требовать определённых форм участия.
Главный вывод из этого исследования заключается в том, что автономия, которой обладают агенты в процессе работы, формируется совместно моделью, пользователем и продуктом. Claude ограничивает свою собственную независимость, делая паузы и задавая вопросы, когда он не уверен. Пользователи развивают доверие в процессе работы с моделью и соответствующим образом корректируют свою стратегию контроля. То, что мы наблюдаем при внедрении, является результатом взаимодействия всех трёх этих факторов, поэтому это нельзя полностью описать только на основе оценок, проведённых до внедрения. Чтобы понять, как агенты фактически ведут себя, необходимо измерять их в реальных условиях, и инфраструктура для этого всё ещё находится в стадии разработки.
Авторы
Майлз Маккейн, Томас Миллар, Сафрон Хуан, Джейк Итон, Кунал Хanda, Майкл Стерн, Алекс Тамкин, Мэтт Керни, Эсин Дурмус, Джуди Шен, Джерри Хонг, Брайан Калверт, Джун Шерн Чан, Франческо Москони, Дэвид Соундерс, Тайлер Нейлон, Габриэль Николас, Сара Поллок, Джек Кларк, Дип Гангули.